Поиск
Показаны результаты для тегов 'вебархивы'.
Найдено 1 результат
-
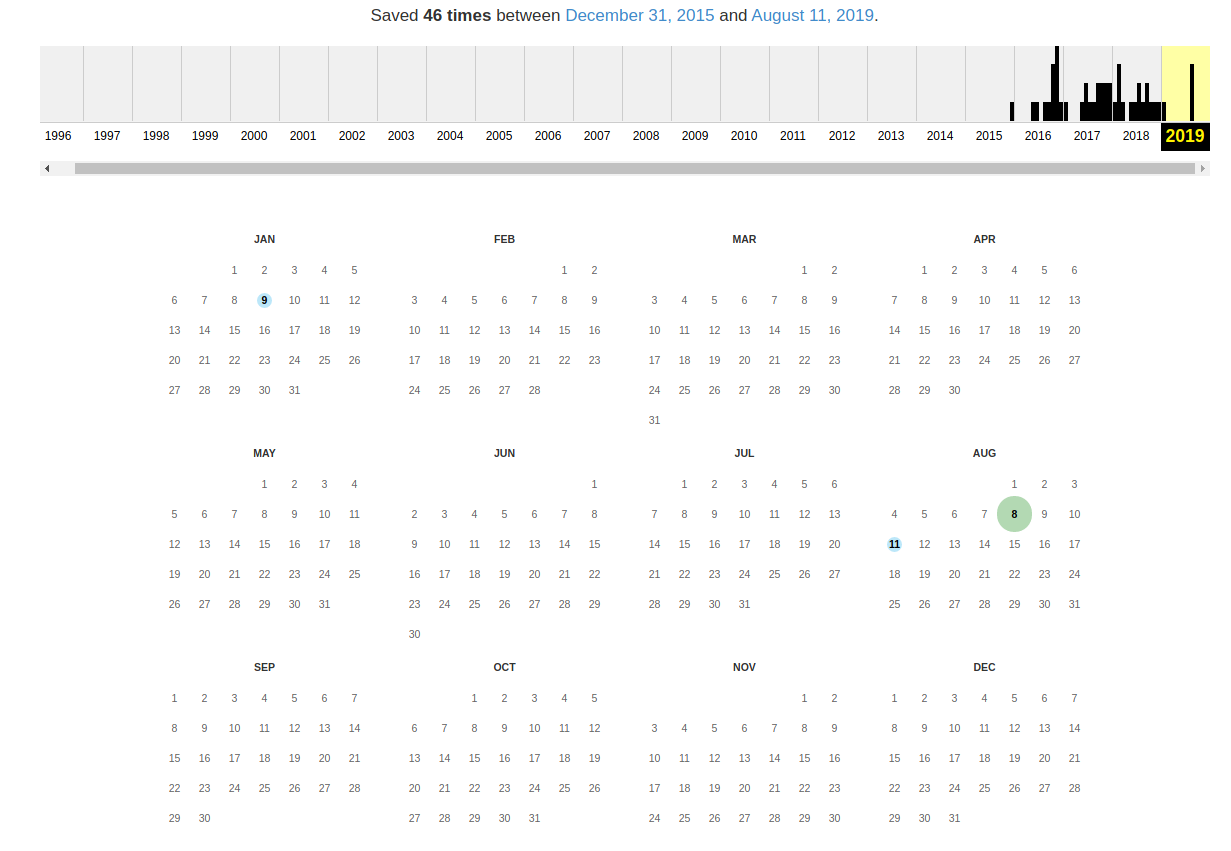
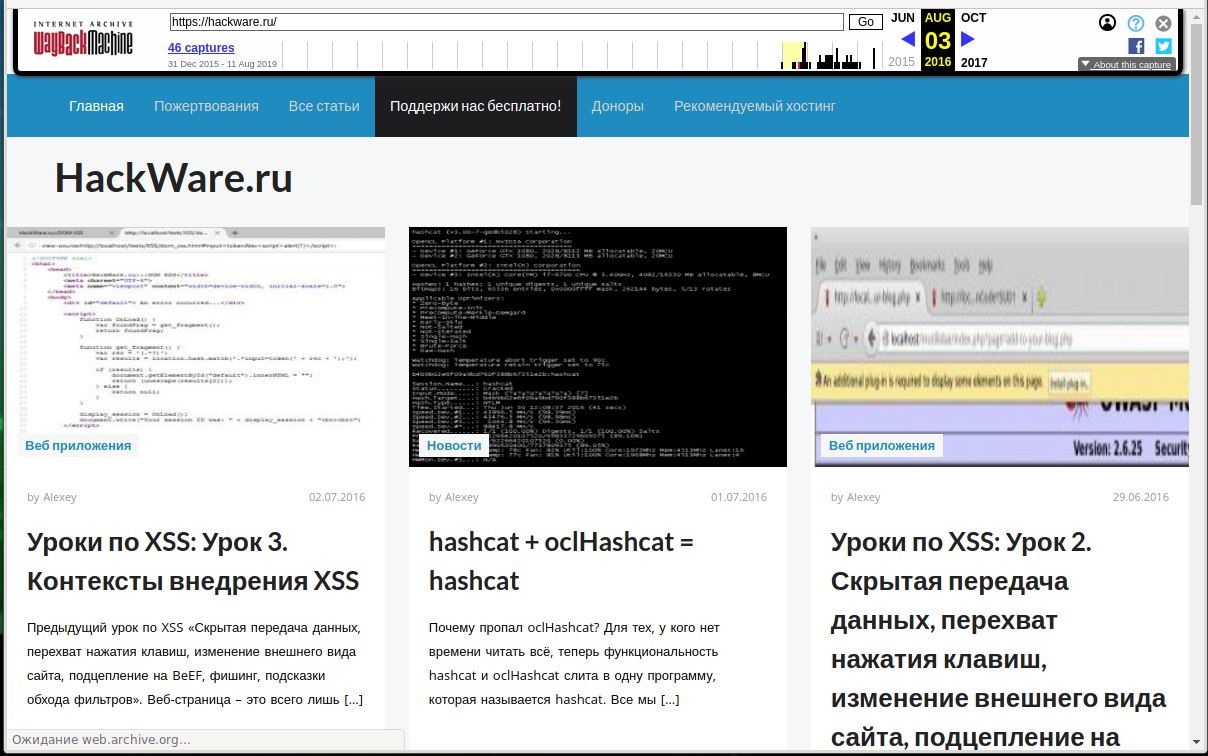
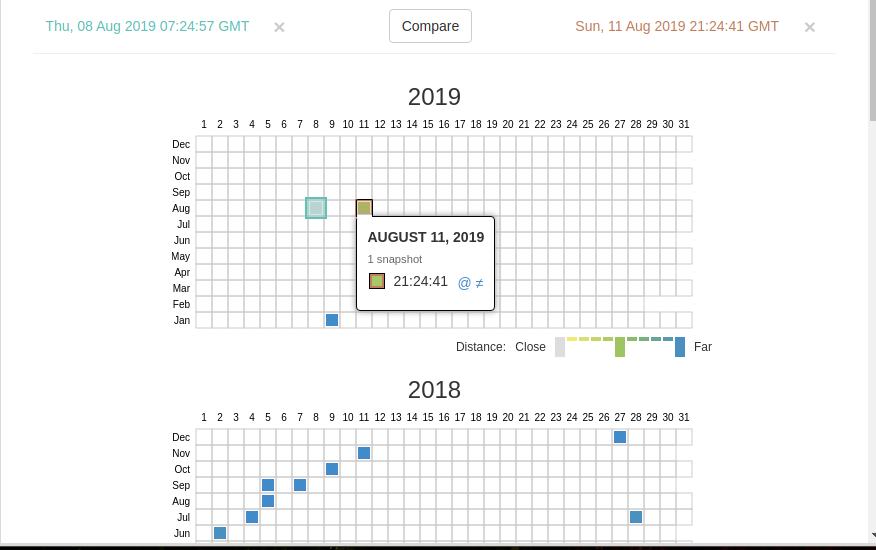
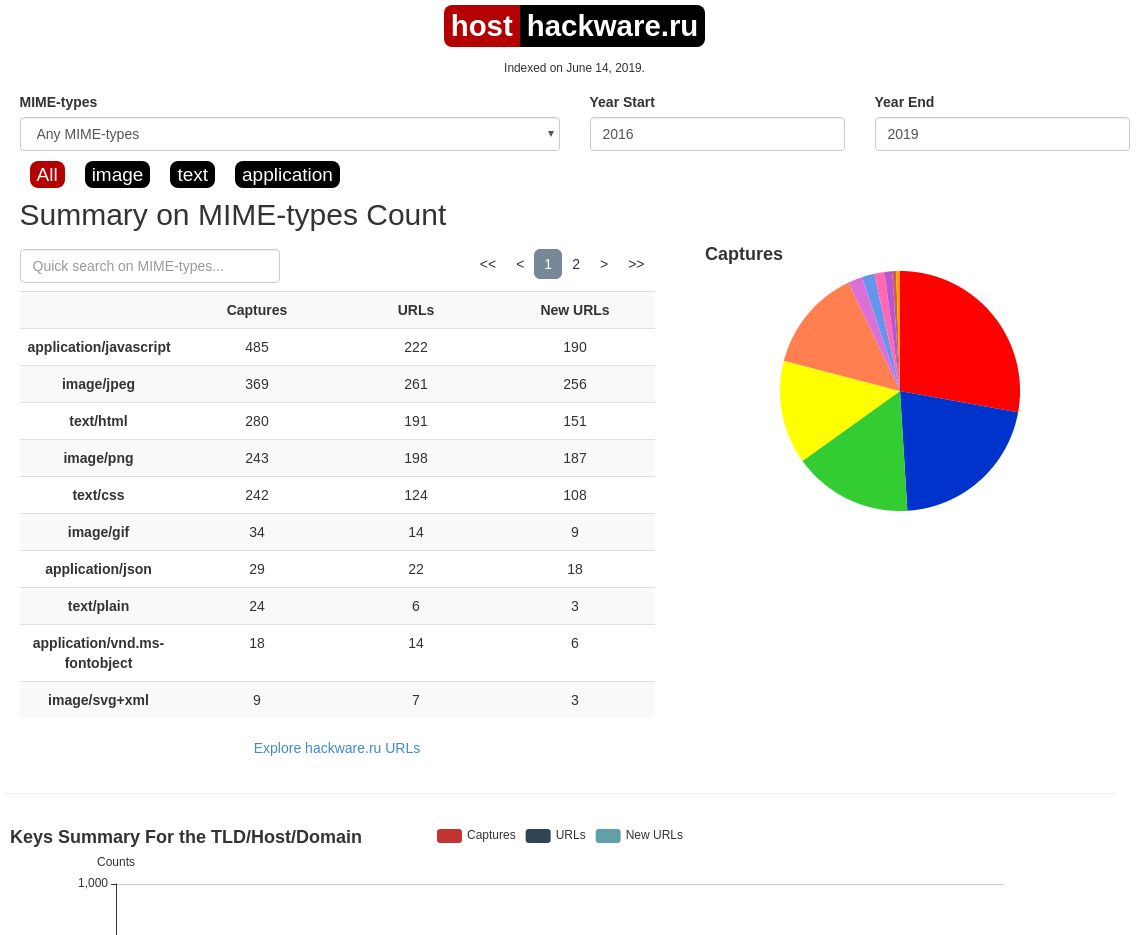
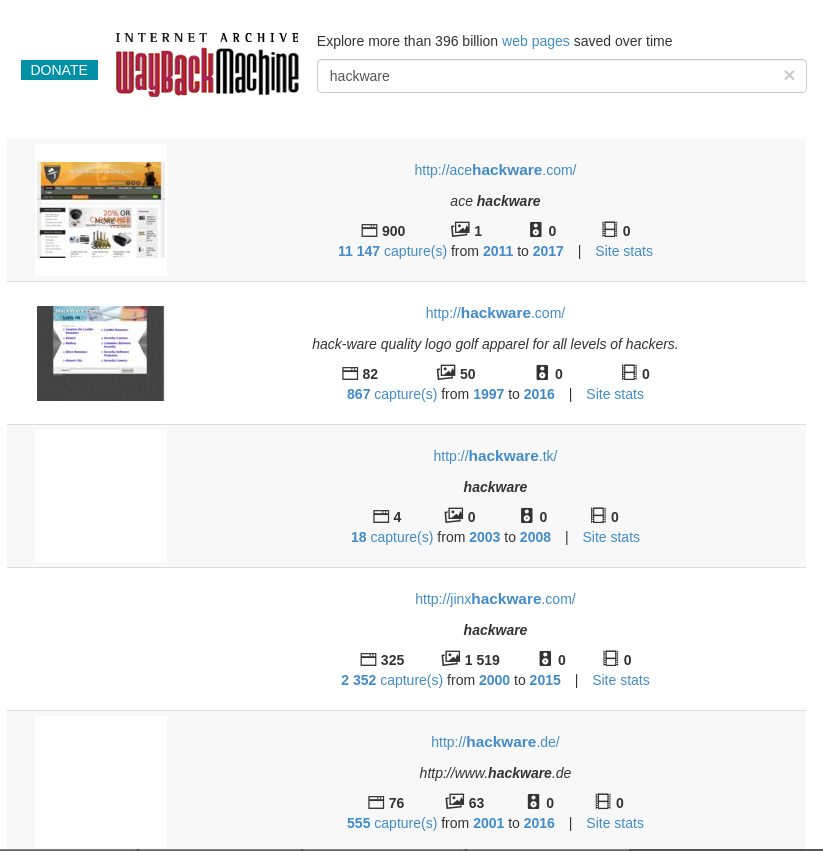
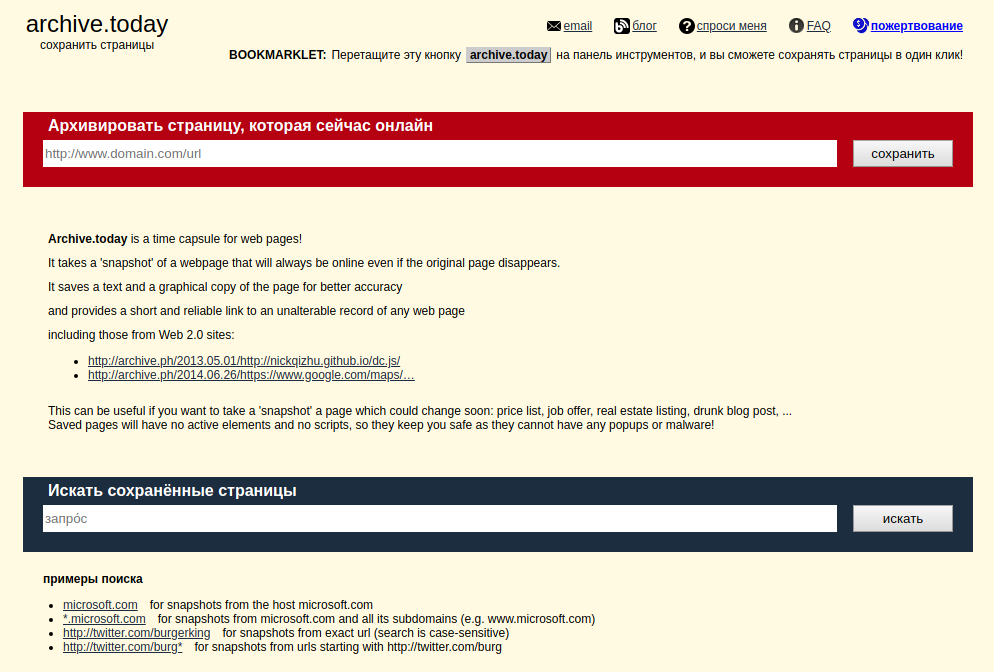
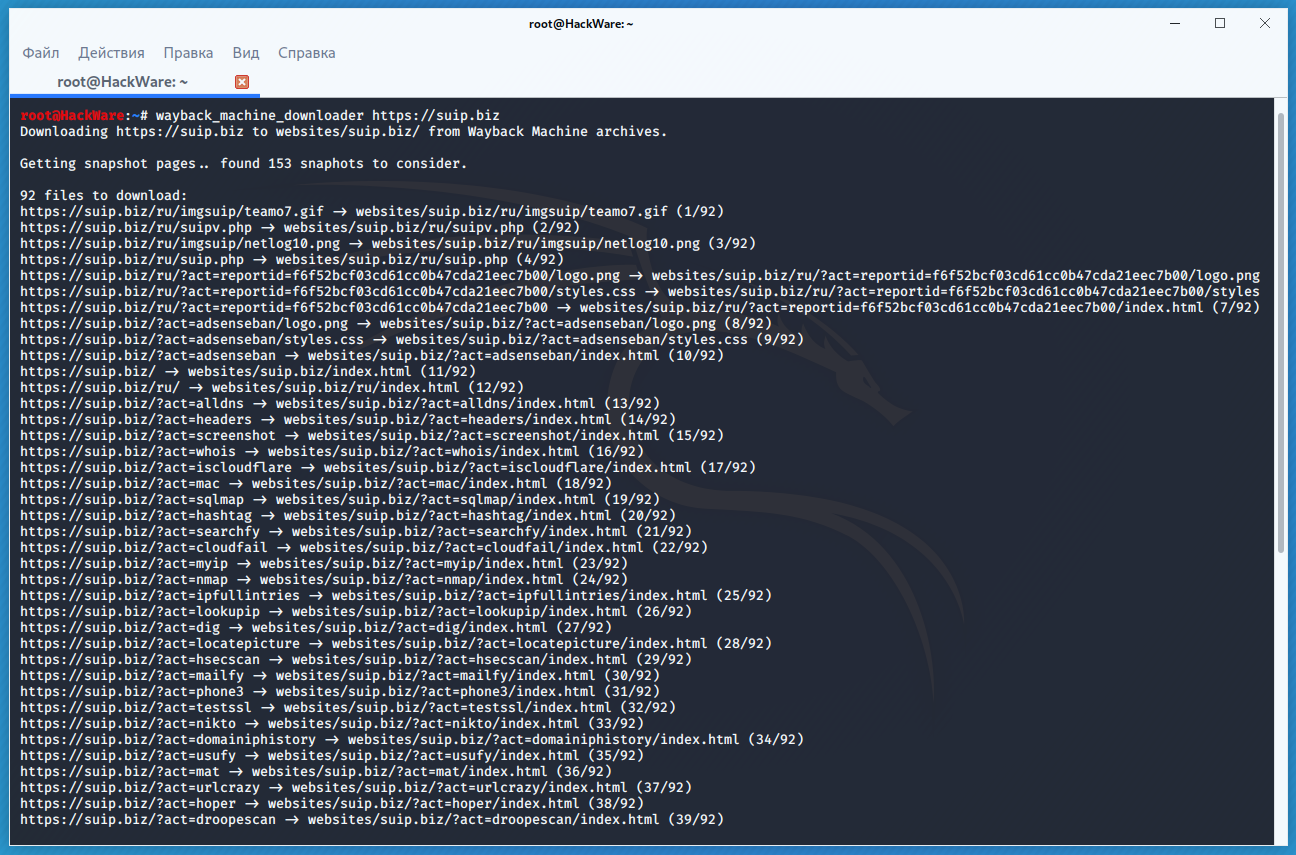
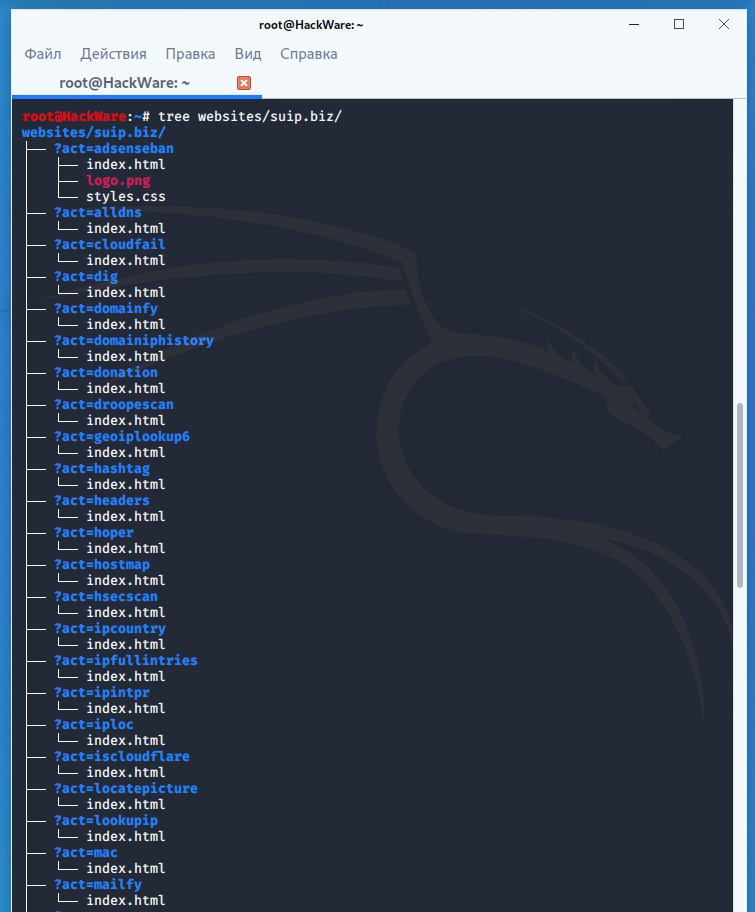
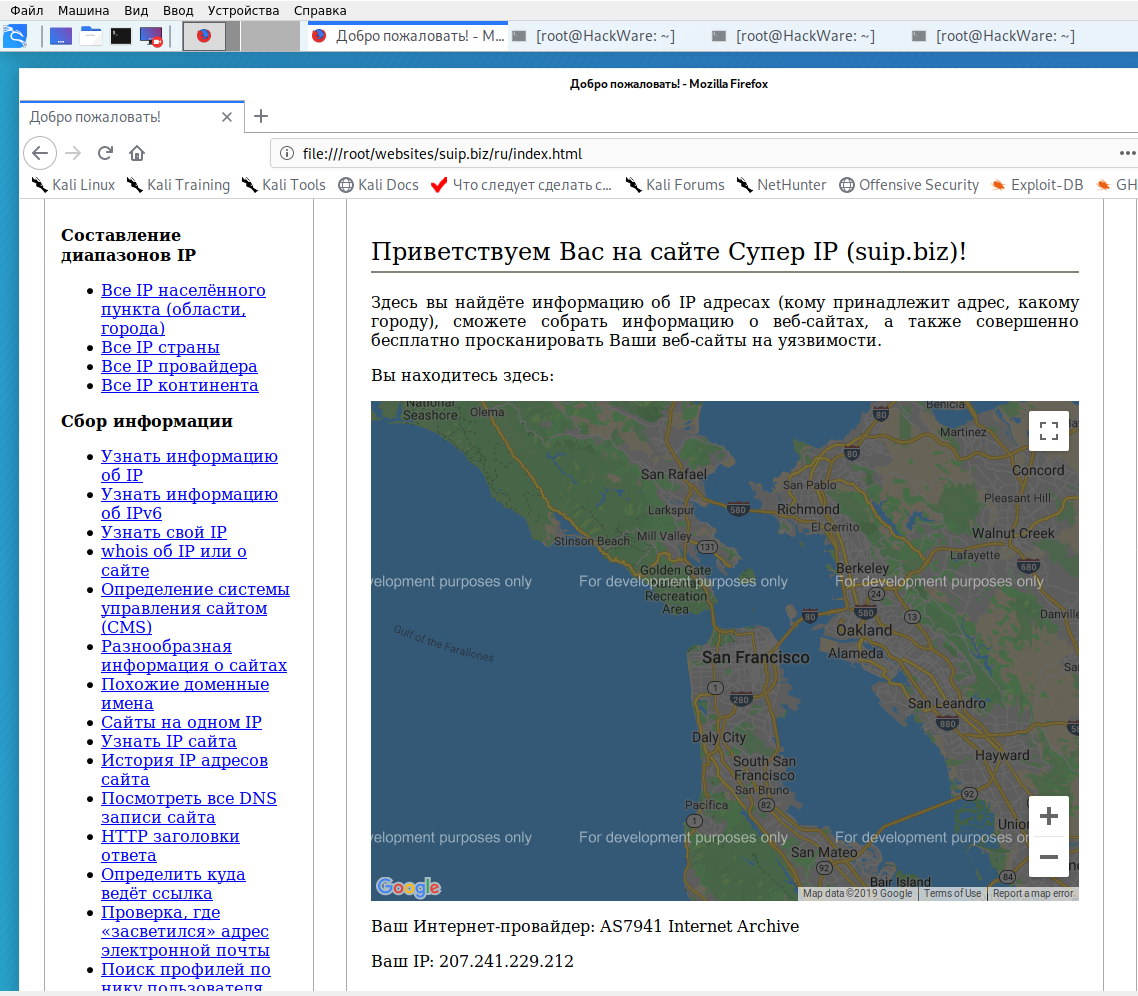
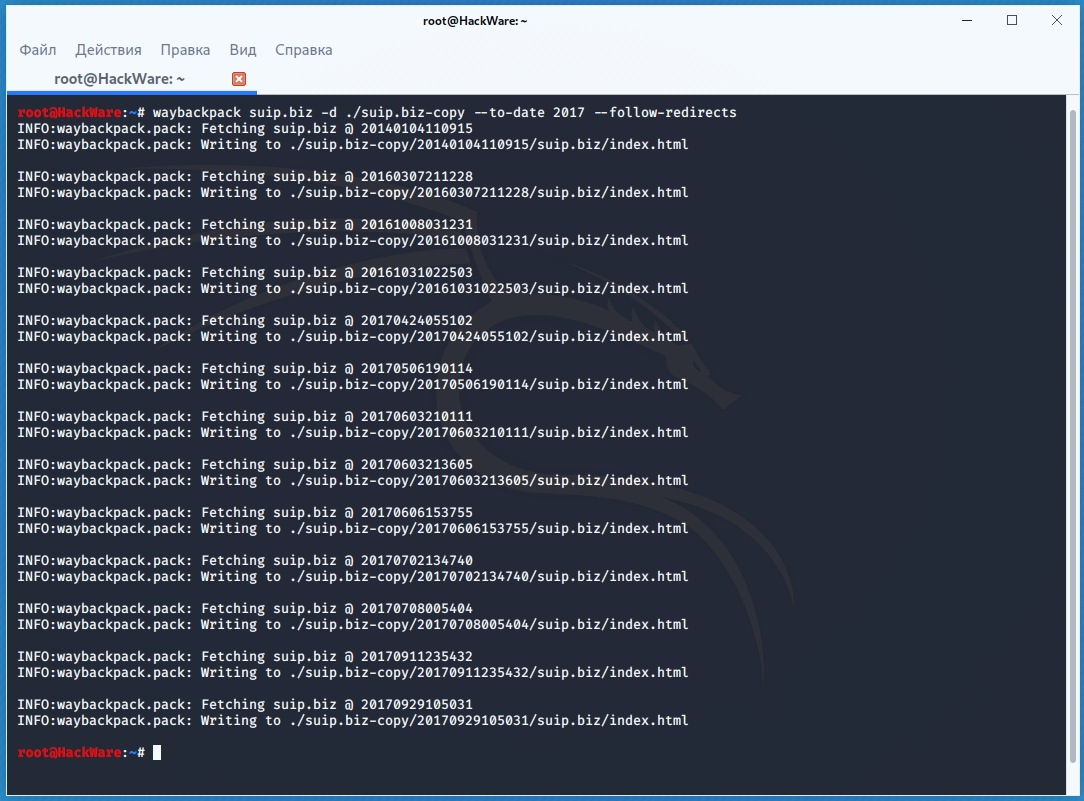
Wayback Machine и Архивы Интернета. Принцип работы всех Интернет Архивов схожий: кто-то (любой пользователь) указывает страницу для сохранения. Интернет Архив скачивает её, в том числе текст, изображения и стили оформления, а затем сохраняет. По запросу сохранённые страницу могут быть просмотрены из Интернет Архива, при этом не имеет значения, если исходная страница изменилась или сайт в данный момент недоступен или вовсе перестал существовать. Многие Интернет Архивы хранят несколько версий одной и той же страницы, делая её снимок в разное время. Благодаря этому можно проследить историю изменения сайта или веб-страницы в течение всех лет существования. В этой статье будет показано, как находить удалённую или изменённую информацию, как использовать Интернет Архивы для восстановления сайтов, отдельных страниц или файлов, а также некоторые другие случае использования. Wayback Machine — это название одного из популярного веб архива сайтов. Иногда Wayback Machine используется как синоним «Интернет Архив». Примеры сайтов веб-архивов: https://web.archive.org/ http://archive.md/ (также использует домены http://archive.ph/ и http://archive.today/) http://web-arhive.ru/ web.archive.org Этот сервис веб архива ещё известен как Wayback Machine. Имеет разные дополнительные функции, чаще всего используется инструментами по восстановлению сайтов и информации. Для сохранения страницы в архив перейдите по адресу https://archive.org/web/ введите адрес интересующей вас страницы и нажмите кнопку «SAVE PAGE». Для просмотра доступных сохранённых версий веб-страницы, перейдите по адресу https://archive.org/web/, введите адрес интересующей вас страницы или домен веб-сайта и нажмите «BROWSE HISTORY»: В самом верху написано, сколько всего снимком страницы сделано, дата первого и последнего снимка. Затем идёт шкала времени на которой можно выбрать интересующий год, при выборе года, будет обновляться календарь. Обратите внимание, что календарь показывает не количество изменений на сайте, а количество раз, когда был сделан архив страницы. Точки на календаре означают разные события, разные цвета несут разный смысл о веб захвате. Голубой означает, что при архивации страницы от веб-сервера был получен код ответа 2nn (всё хорошо); зелёный означает, что архиватор получил статус 3nn (перенаправление); оранжевый означает, что получен статус 4nn (ошибка на стороне клиента, например, страница не найдена), а красный означает, что при архивации получена ошибка 5nn (проблемы на сервере). Вероятно, чаще всего вас должны интересовать голубые и зелёные точки и ссылки. При клике на выбранное время, будет открыта ссылка, например, http://web.archive.org/web/20160803222240/https://hackware.ru/ и вам будет показано, как выглядела страница в то время: Используя эту миниатюру вы сможете переходить к следующему снимку страницы, либо перепрыгнуть к нужной дате: Лучший способ увидеть все файлы, которые были архивированы для определённого сайта, это открыть ссылку вида http://web.archive.org/*/www.yoursite.com/*, например, http://web.archive.org/*/hackware.ru/ Кроме календаря доступна следующие страницы: Collections — коллекции. Доступны как дополнительные функции для зарегистрированных пользователей и по подписке Changes Summary Site Map Changes "Changes" — это инструмент, который вы можете использовать для идентификации и отображения изменений в содержимом заархивированных URL. Начать вы можете с того, что выберите два различных дня какого-то URL. Для этого кликните на соответствующие точки и нажмите кнопку Compare. В результате будут показаны два варианта страницы. Жёлтый цвет показывает удалённый контент, а голубой цвет показывает добавленный контент. Summary В этой вкладке статистика о количестве изменений MIME-типов: Site Map Как следует из название, здесь показывается диаграмма карты сайта, используя которую вы можете перейти к архиву интересующей вас страницы. Поиск по Интернет архиву. Если вместо адреса страницы вы введёте что-то другое, то будет выполнен поиск по архивированным сайтам: Показ страницы на определённую дату Кроме использования календаря для перехода к нужной дате, вы можете просмотреть страницу на нужную дату используя ссылку следующего вида: http://web.archive.org/web/ГГГГММДДЧЧММСС/АДРЕС_СТРАНИЦЫ/ Обратите внимание, что в строке ГГГГММДДЧЧММСС можно пропустить любое количество конечных цифр. Если на нужную дату не найдена архивная копия, то будет показана версия на ближайшую имеющуюся дату. archive.md Адреса данного Архива Интернета: http://archive.md http://archive.ph/ http://archive.today/ На главной странице говорящие за себя поля: Архивировать страницу, которая сейчас онлайн Искать сохранённые страницы Для поиска по сохранённым страницам можно как указывать конкретный URL, так и домены, например: microsoft.com покажет снимки с хоста microsoft.com *.microsoft.com покажет снимки с хоста microsoft.com и всех его субдоменов (например, www.microsoft.com) http://twitter.com/burgerkingfor покажет архив данного url (поиск чувствителен к регистру) http://twitter.com/burg* поиск архивных url начинающихся с http://twitter.com/burg Данный сервис сохраняет следующие части страницы: Текстовое содержимое веб страницы Изображения Содержимое фреймов Контент и изображения загруженные или сгенерированные с помощью Javascript на сайтах Web 2.0 Скриншоты размером 1024×768 пикселей. Не сохраняются следующие части веб-страниц: Flash и загружаемый им контент Видео и звуки PDF RSS и другие XML-страницы сохраняются ненадёжно. Большинство из них не сохраняются, или сохраняются как пустые страницы. Архивируемая страница и все изображения должны быть менее 50 Мегабайт. Для каждой архивированной страницы создаётся ссылка вида http://archive.is/XXXXX, где XXXXX это уникальный идентификатор страницы. Также к любой сохранённой странице можно получить доступ следующим образом: http://archive.is/2013/http://www.google.de/ — самый новый снимок в 2013 году. http://archive.is/201301/http://www.google.de/ — самый новый снимок в январе 2013. http://archive.is/20130101/http://www.google.de/ — самый новый снимок в течение дня 1 января 2013. Дату можно продолжить далее, указав часы, минуты и секунды: http://archive.is/2013010103/http://www.google.de/ http://archive.is/201301010313/http://www.google.de/ http://archive.is/20130101031355/http://www.google.de/ Для улучшения читаемости, год, месяц, день, часы, минуты и секунды могут быть разделены точками, тире или двоеточиями: http://archive.is/2013-04-17/http://blog.bo.lt/ http://archive.is/2013.04.17-12:08:20/http://blog.bo.lt/ Также возможно обратиться ко всем снимкам указанного URL: http://archive.is/http://www.google.de/ Все сохранённые страницы домена: http://archive.is/www.google.de Все сохранённые страницы всех субдоменов http://archive.is/*.google.de Чтобы обратиться к самой последней версии страницы в архиве или к самой старой, поддерживаются адреса вида: http://archive.is/newest/http://reddit.com/ http://archive.is/oldest/http://reddit.com/ Чтобы обратиться к определённой части длинной страницы имеется две опции: добавить хэштег (#) с позицией прокрутки в качество которого число между 0 (вершина страницы) и 100 (низ страницы). Например, http://archive.md/dva4n#95% выбрать текст на страницы и получить URL с хэштегом, указывающим на этот раздел. Например, http://archive.is/FWVL#selection-1493.0-1493.53 В доменах поддерживаются национальные символы: http://archive.is/www.maroñas.com.uy http://archive.is/*.测试 Обратите внимание, что при создании архивной копии страницы архивируемому сайту отправляется IP адрес человека, создающего снимок страницы. Это делается через заголовок X-Forwarded-For для правильного определения вашего региона и показа соответствующего содержимого. web-arhive.ru Архив интернет (Web archive) — это бесплатный сервис по поиску архивных копий сайтов. С помощью данного сервиса вы можете проверить внешний вид и содержимое страницы в сети интернет на определённую дату. На момент написания, этот сервис, вроде бы, нормально не работает («Database Exception (#2002)»). Если у вас есть по нему какие-то новости, то пишите их в комментариях. Поиск сразу по всем Веб-архивам Может так случиться, что интересующая страница или файл отсутствует в веб архиве. В этом случае можно попытаться найти интересующую сохранённую страницу в другом Архиве Интернета. Специально для этого я сделал довольно простой сервис, который для введённого адреса даёт ссылки на снимки страницы в рассмотренных трёх архивах. Адрес сервиса: https://suip.biz/ru/?act=web-arhive Что делать, если удалённая страница не сохранена ни в одном из архивов? Архивы Интернета сохраняют страницы только если какой-то пользователь сделал на это запрос — они не имеют функции обходчиков и ищут новые страницы и ссылки. По этой причине возможно, что интересующая вас страница оказалась удалено до того, как была сохранена в каком-либо веб-архиве. Тем не менее можно воспользоваться услугами поисковых движков, которые активно ищут новые ссылки и оперативно сохраняют новые страницы. Для показа страницы из кэша Google нужно в поиске Гугла ввести 1 cache:URL Например: 1 cache:https://hackware.ru/?p=6045 Если ввести подобный запрос в поиск Google, то сразу будет открыта страница из кэша. Для просмотра текстовой версии можно использовать ссылку вида: http://webcache.googleusercontent.com/search?q=cache:URL&strip=1&vwsrc=0 Для просмотра исходного кода веб страницы из кэша Google используйте ссылку вида: http://webcache.googleusercontent.com/search?q=cache:URL&strip=0&vwsrc=1 Например, текстовый вид: http://webcache.googleusercontent.com/search?q=cache:https://hackware.ru/?p=6045&strip=1&vwsrc=0 Исходный код: http://webcache.googleusercontent.com/search?q=cache:https://hackware.ru/?p=6045&strip=0&vwsrc=1 Как полностью скачать сайт из веб-архива Если вы хотите восстановить удалённый сайт, то вам поможет программа Wayback Machine Downloader. Программа загрузит последнюю версию каждого файла, присутствующего в Архиве Интернета Wayback Machine, и сохранить его в папку вида ./websites/example.com/. Она также пересоздаст структуру директорий и автоматически создаст страницы index.html чтобы скаченный сайт без каких либо изменений можно было бы поместить на веб-сервер Apache или Nginx. Об установке программы и дополнительных опциях смотрите на странице https://kali.tools/?p=5211 Пример скачивания полной копии сайта suip.biz из веб-архива: 1. wayback_machine_downloader https://suip.biz Структура скаченных файлов: Локальная копия сайта, обратите внимание на провайдера Интернет услуг: Как скачать все изменения страницы из веб-архива Если вас интересует не весь сайт, а определённая страница, но при этом вам нужно проследить все изменения на ней, то в этом случае используйте программу Waybackpack. К примеру для скачивания всех копий главной страницы сайта suip.biz, начиная с даты (—to-date 2017), эти страницы должны быть помещены в папку (-d /home/mial/test), при этом программа должна следовать HTTP редиректам (—follow-redirects): waybackpack suip.biz -d ./suip.biz-copy --to-date 2017 --follow-redirects Структура директорий: Чтобы для указанного сайта (hackware.ru) вывести список всех доступных копий в веб-архиве (—list): waybackpack hackware.ru --list Как узнать все страницы сайта, которые сохранены в веб-архиве Для получения ссылок, которые хранятся в Архиве Интернета, используйте программу waybackurls. Эта программа извлекает все URL указанного домена, о которых знает Wayback Machine. Это можно использовать для быстрого составления карты сайта. Чтобы получить список всех страниц о которых знает Wayback Machine для домена suip.biz: echo suip.biz | waybackurls Заключение Предыдущие три программы рассмотрены совсем кратко. Дополнительную информацию об их установке и об имеющихся опциях вы сможете найти по ссылкам на карточки этих программ. Ещё парочка программ, которые работают с архивом интернета: https://github.com/relrelb/wayback-downloader https://github.com/erlange/wbm-dl