
Лидеры




Популярный контент
Показан контент с высокой репутацией за 21.03.2025 во всех областях
-
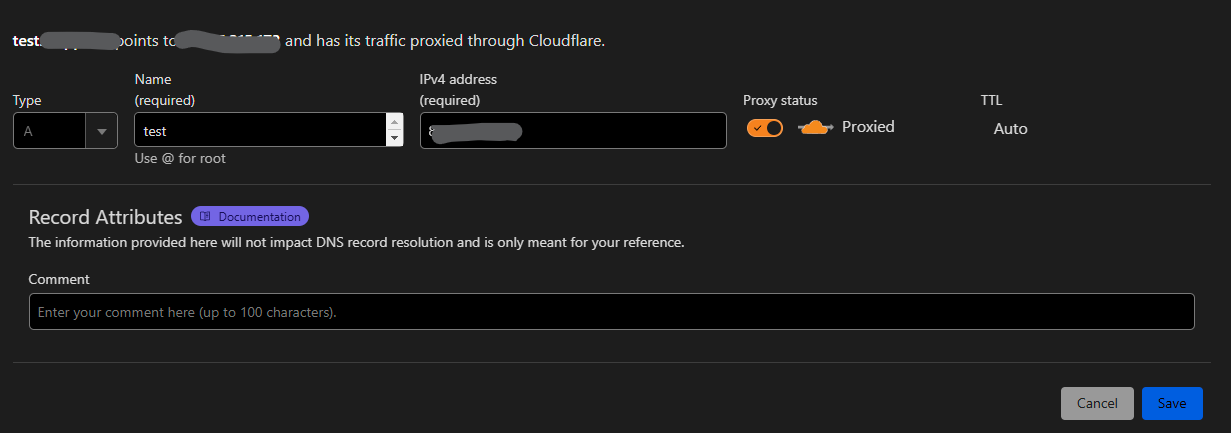
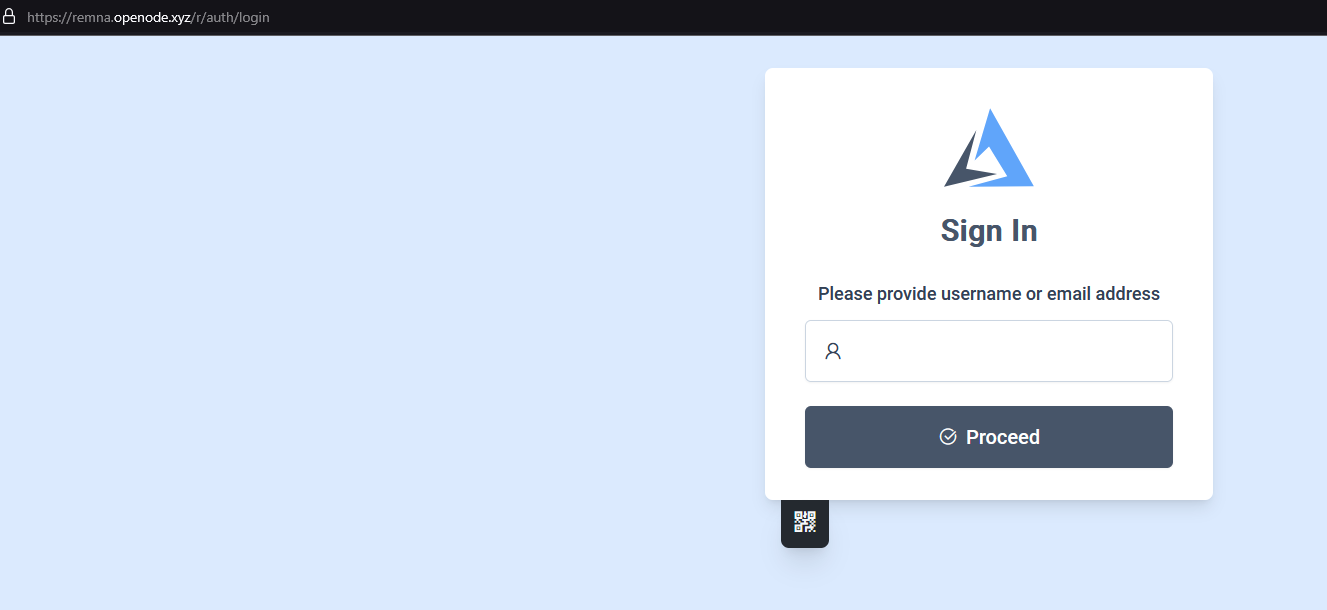
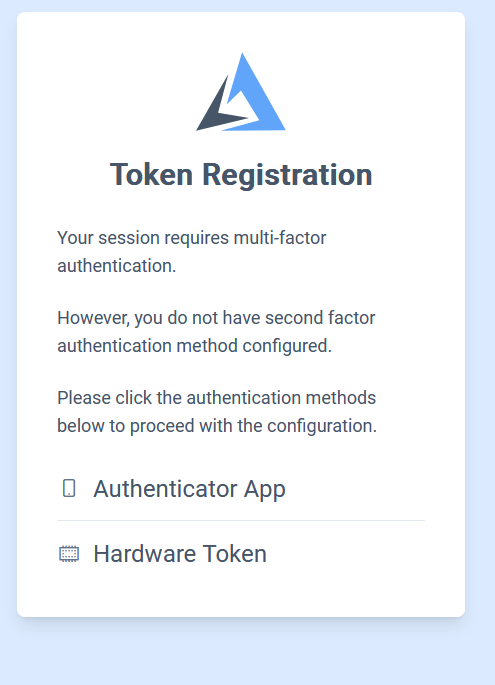
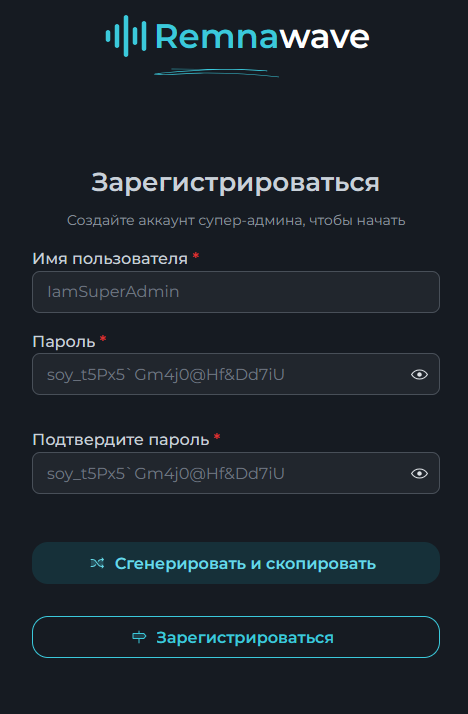
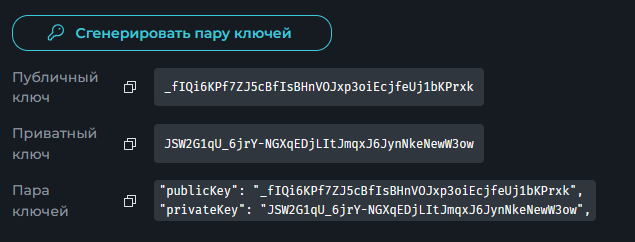
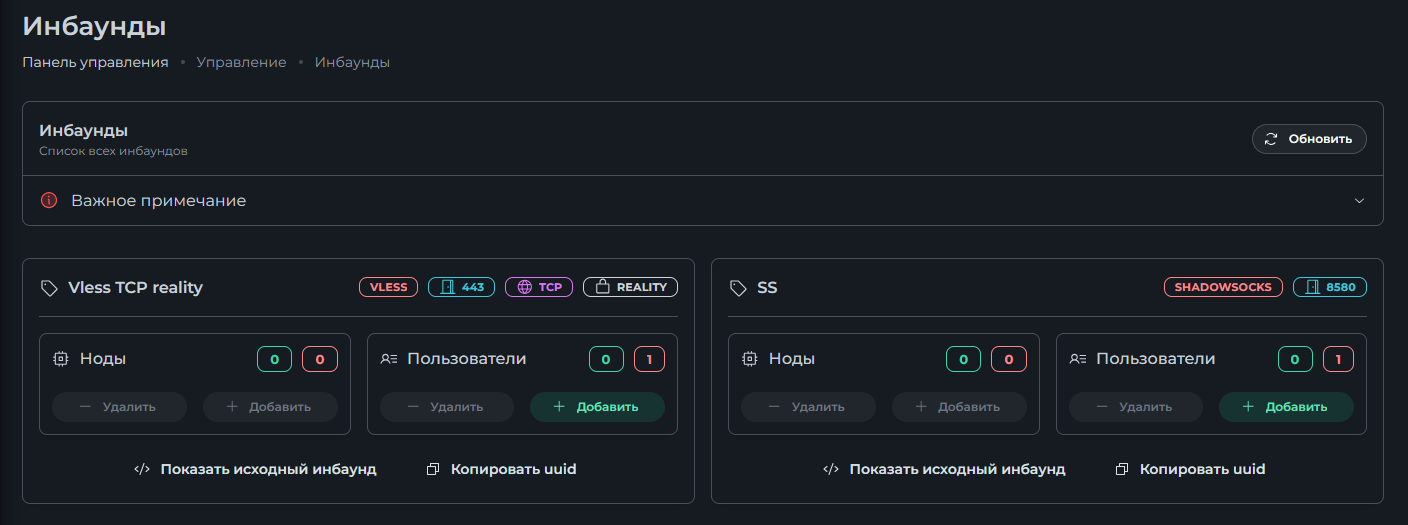
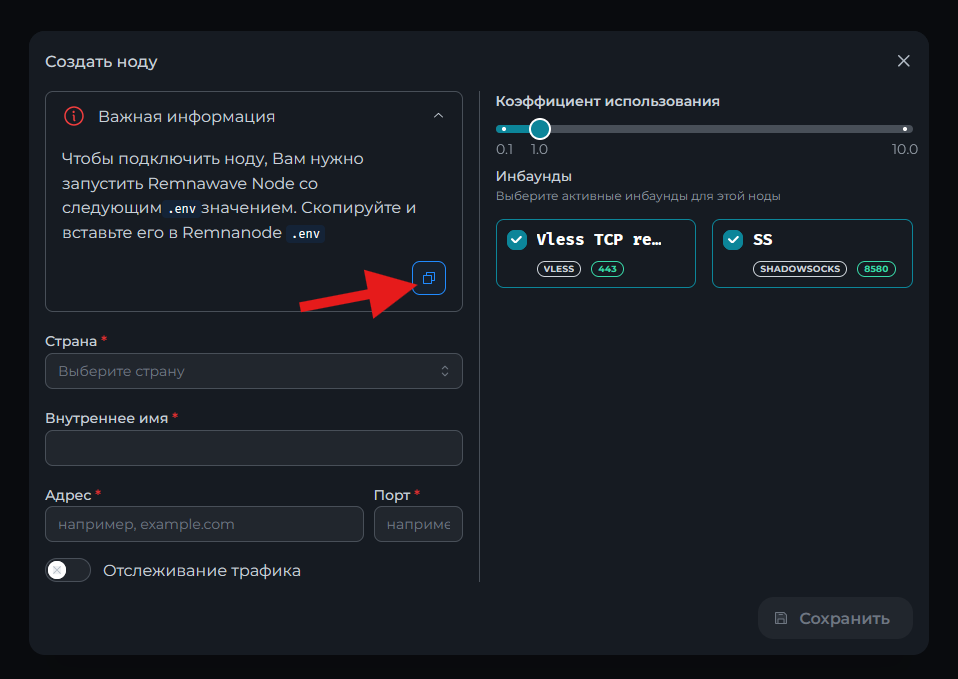
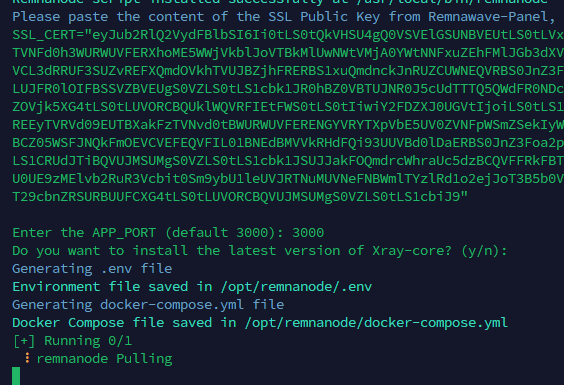
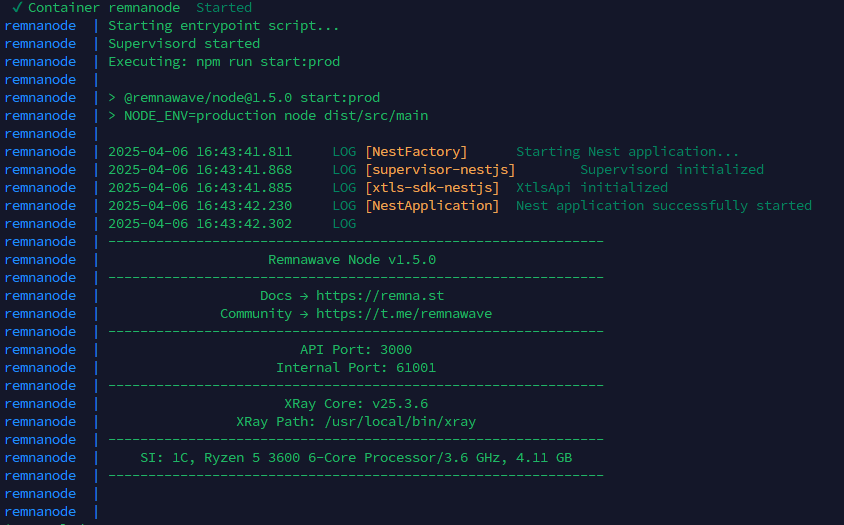
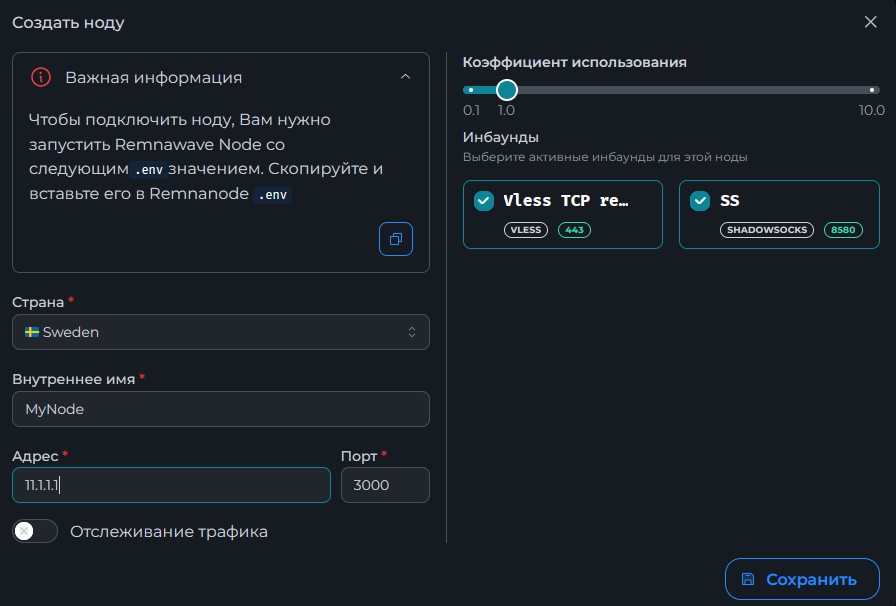
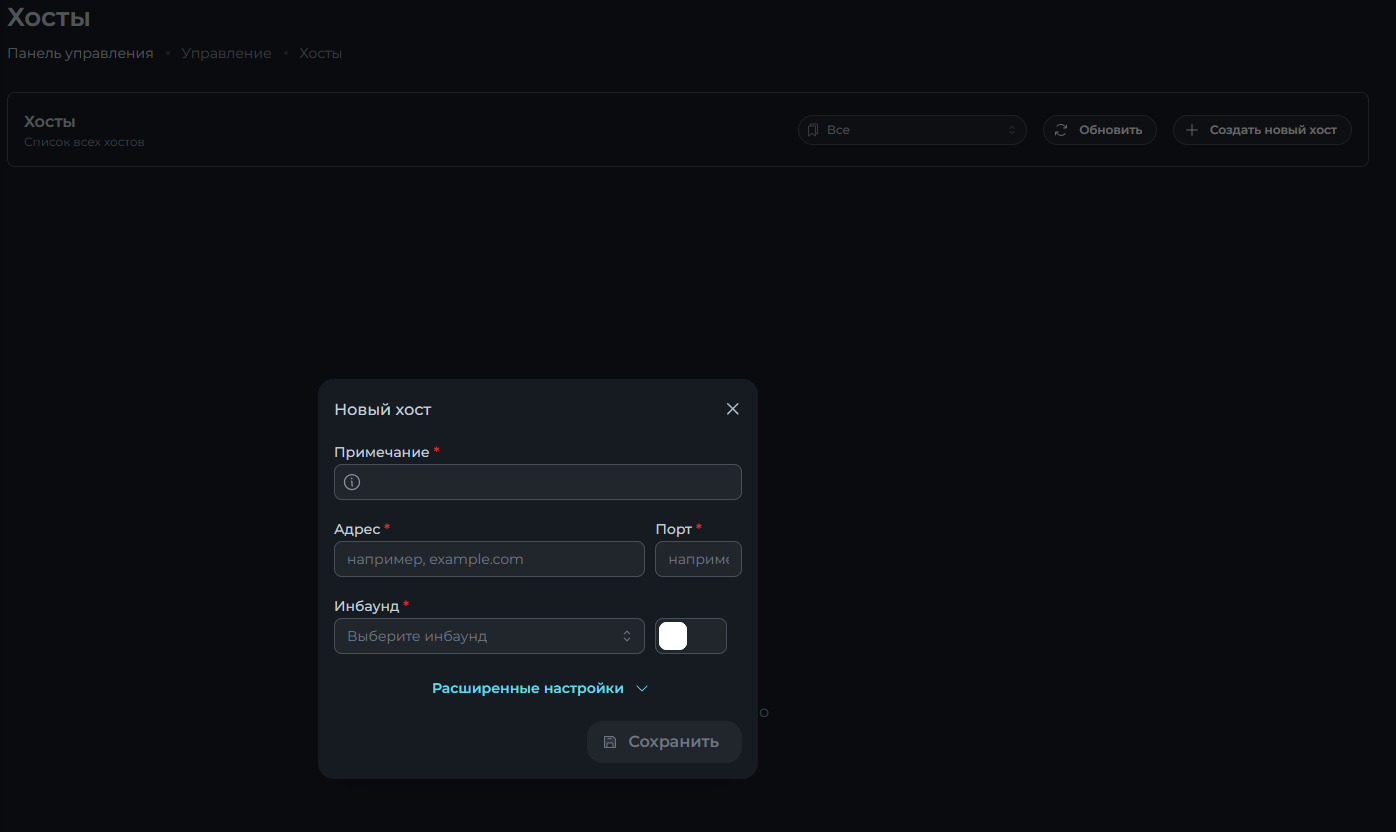
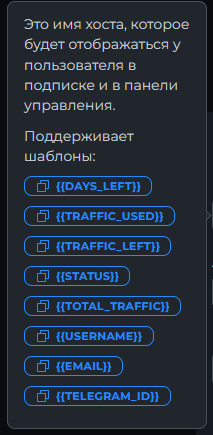
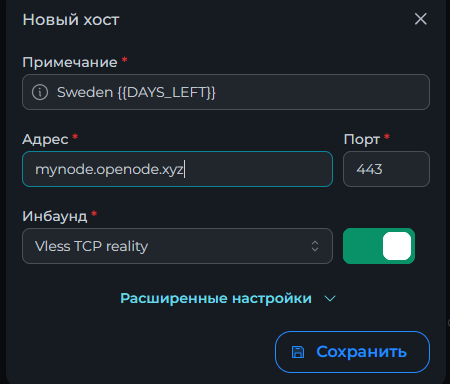
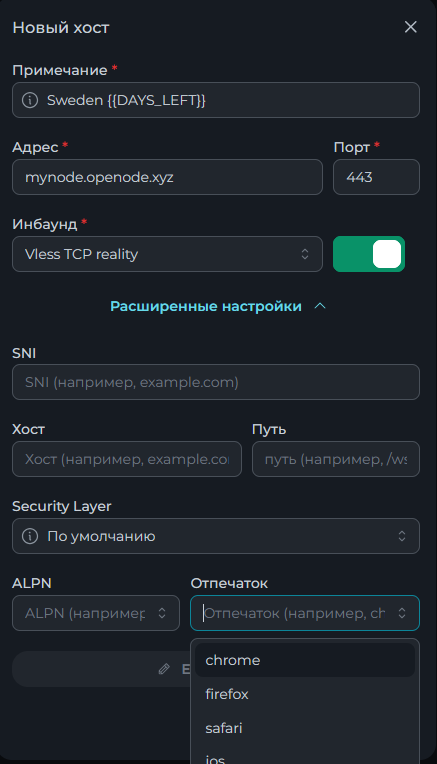
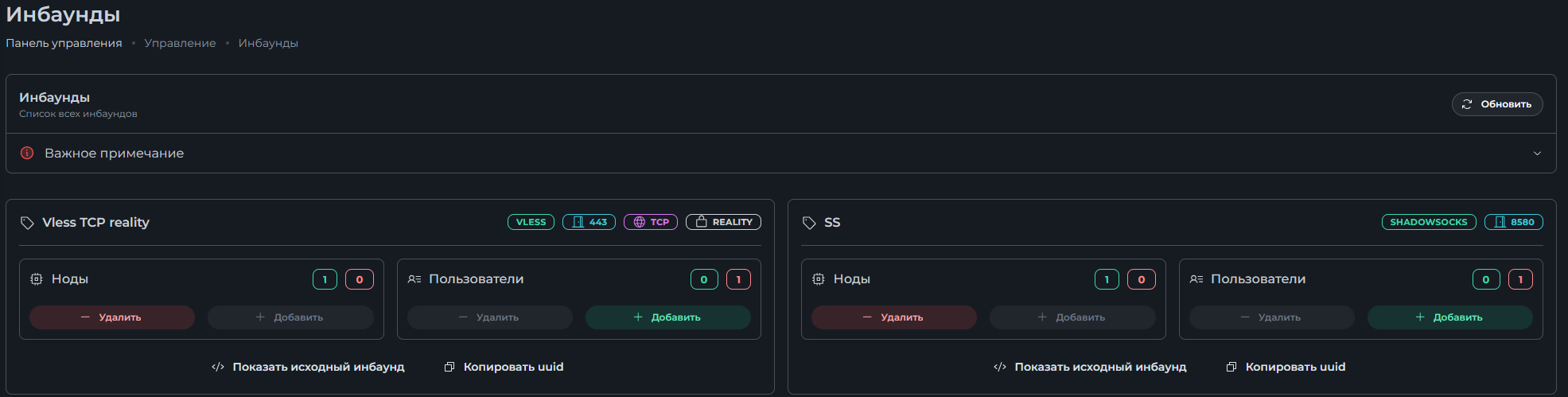
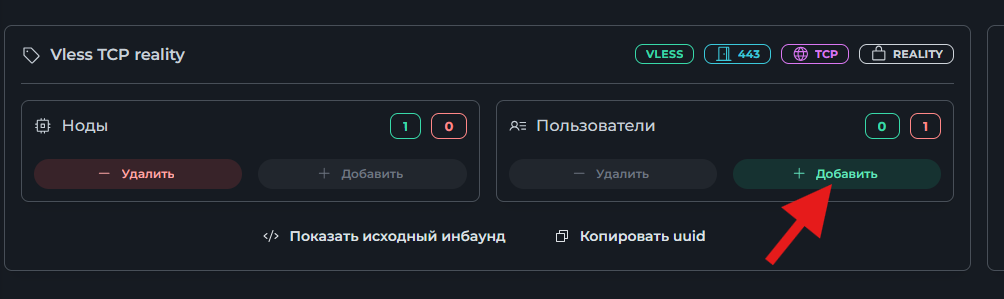
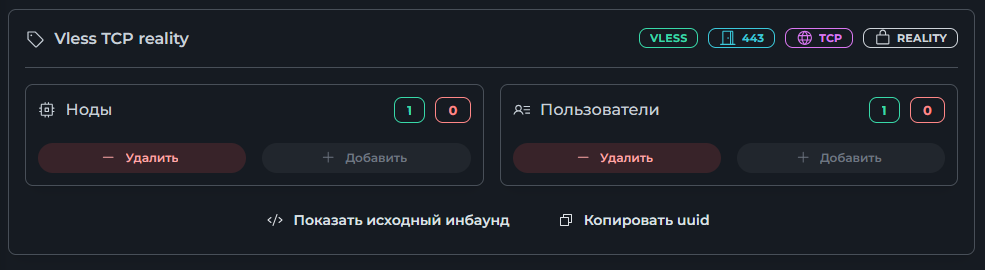
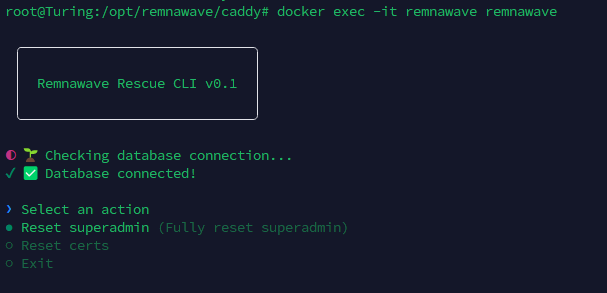
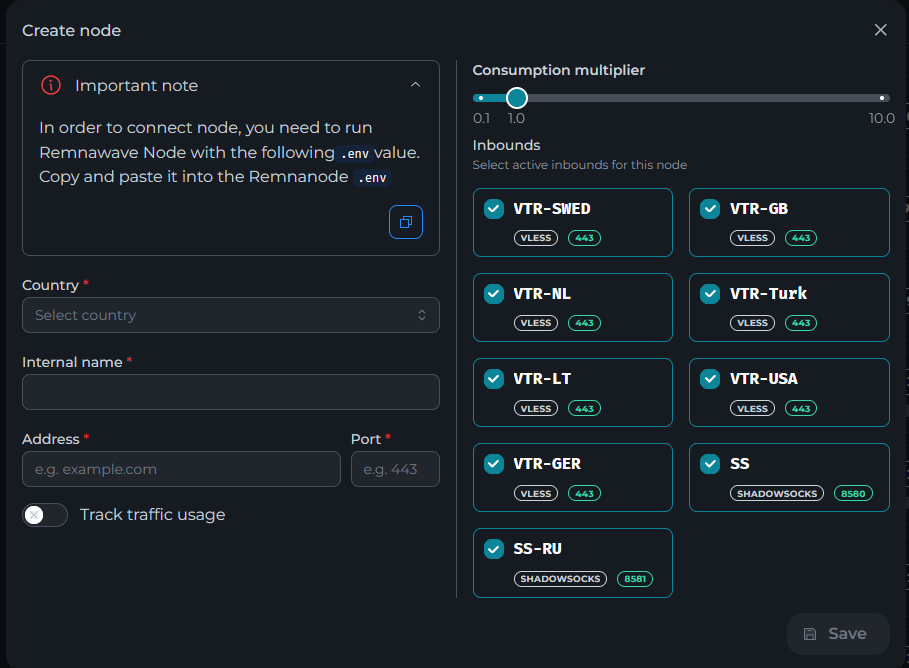
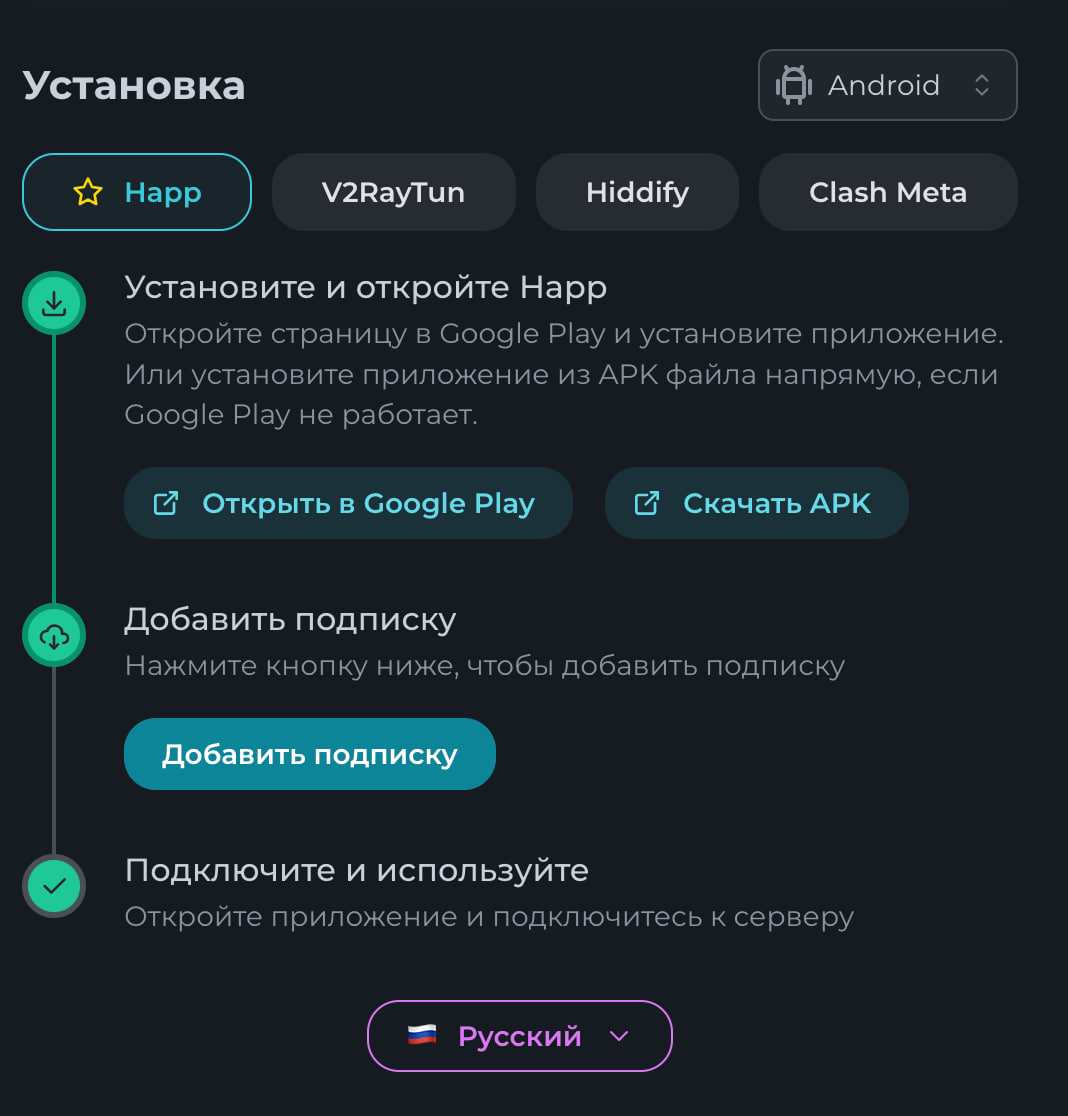
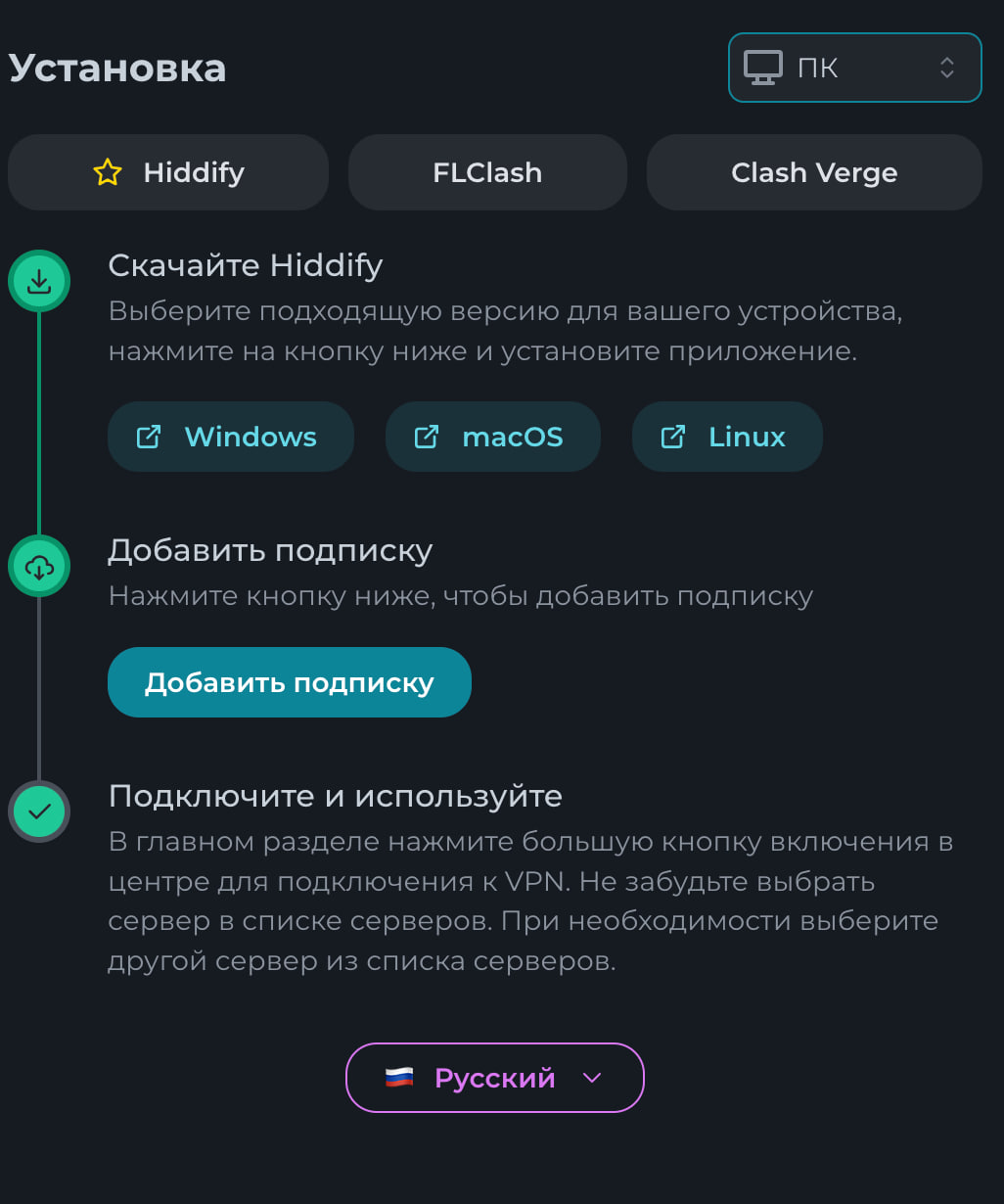
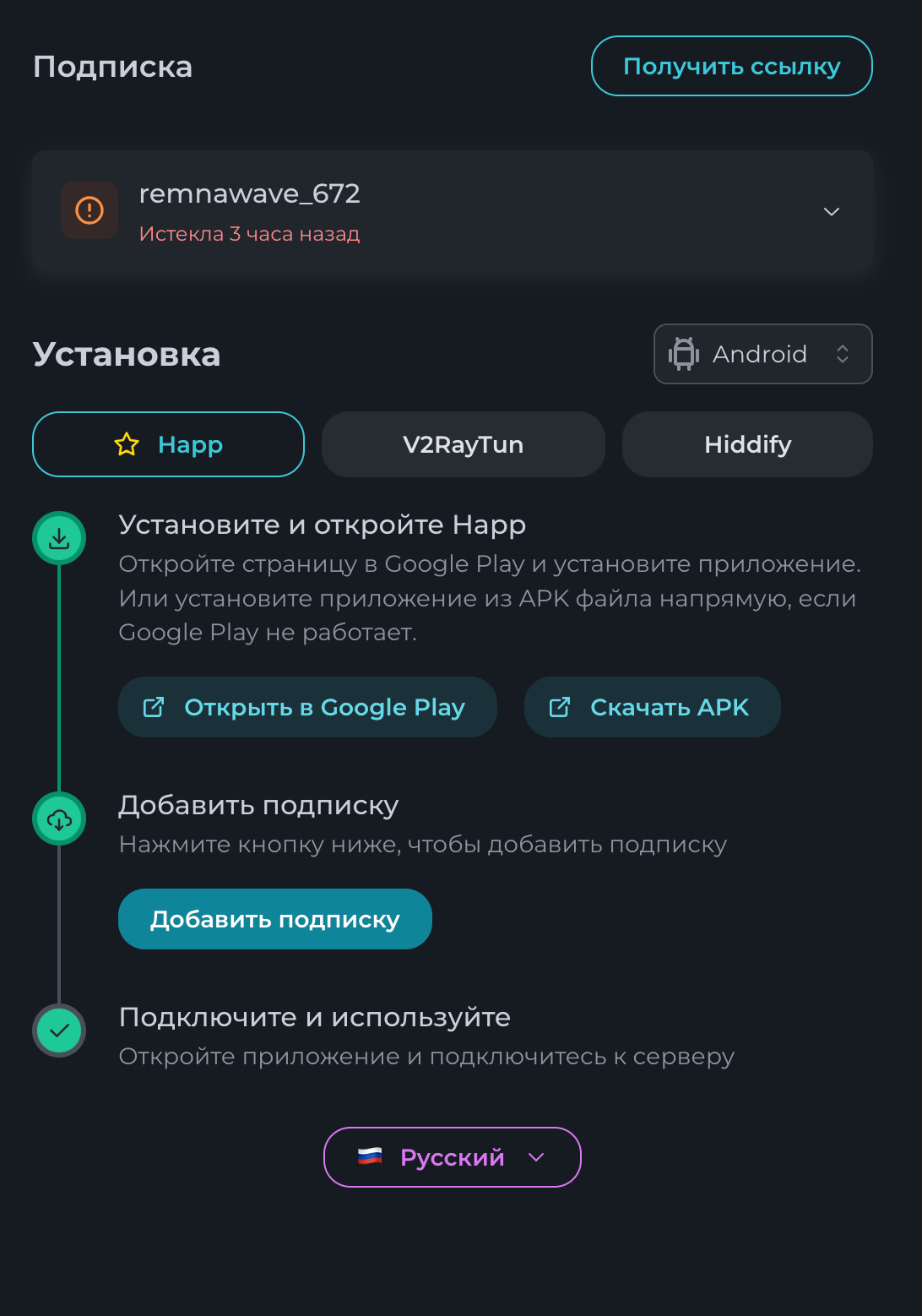
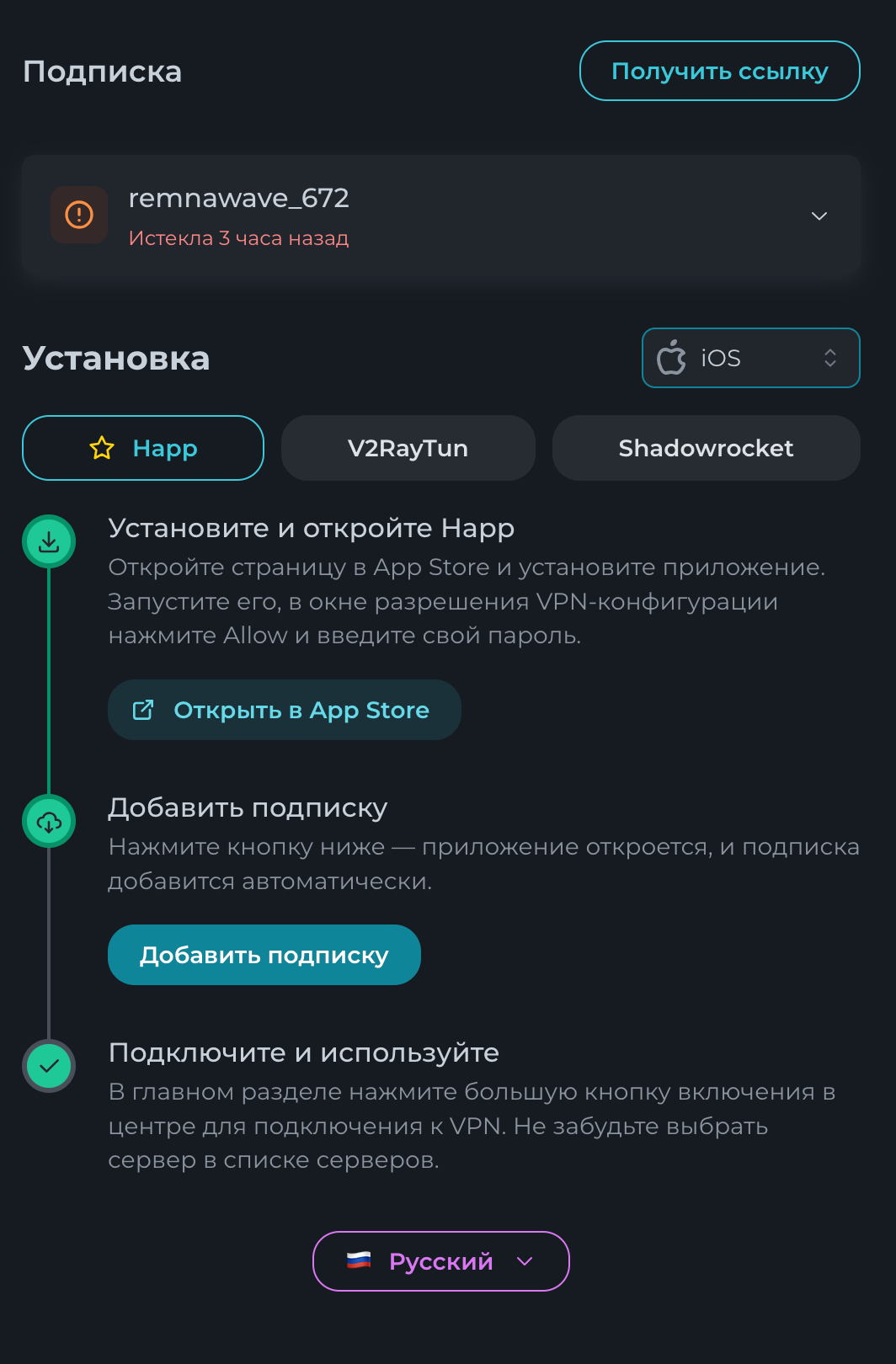
Всем привет! Немного задержавшись с продолжением по личным объективным причинам, продолжаю рассказы. Для чистоты пояснений и инструкций я сделаю все эти действия с нуля и подключу одну ноду. Все данные в статье буду приводить как есть, так как все сервера и домены тестовые, можете ломиться сколько угодно они уже будут удалены. Повторяться сильно не буду, поэтому базовую настройку мы просто повторим. Относительно прошлой статьи мы сразу поменяем место для установки нашей панели. Оно будет по пути: /opt/remnawave 1. Аренда сервера Для начала, как обычно, нам нужно выбрать сервер. 1.1. Рекомендации по аренде Из последнего, что могу посоветовать к аренде: Как бы ни ругались, но проверенный за много лет: 4VPS: https://4vps.su/r/p52GUJhPv8b5 Самый стабильный для мейн-сервера в РФ Selectel: https://selectel.ru/?ref_code=8d43638548 Если нужны стабильные ноды, конечно Kamatera: https://go.cloudwm.com/visit/?bta=36601&nci=5749 2. Подготовка сервера 2.1. Установка Docker Первым делом на новом сервере ставим Docker: curl -fsSL https://get.docker.com | sh 2.2. Создание папки для проекта Remnawave mkdir -p /opt/remnawave/ 2.3. Переход в папку cd /opt/remnawave/ 2.4. Настройка домена в Cloudflare Идем в панель Cloudflare. Добавляем домен и привязываем к своему серверу (надеюсь, вы знаете, как это делать): remna.openode.xyz 2.5. Настройка страницы подписки Аналогично делаем для страницы подписки. У меня это будет: link.openode.xyz Отлично. 2.6. Установка Caddy Caddy мы будем ставить по инструкции с двухфакторной аутентификацией: https://remna.st/security/caddy-with-minimal-setup Создаем папку для Caddy. Caddy у нас будет работать в Docker, так проще для старта. Но вы можете делать на свое усмотрение. mkdir -p /opt/remnawave/caddy && cd /opt/remnawave/caddy 2.7. Создание файла Caddyfile Создаем файл Caddyfile: nano /opt/remnawave/caddy/Caddyfile Прописываем в него: { order authenticate before respond order authorize before respond security { local identity store localdb { realm local path /data/.local/caddy/users.json } authentication portal remnawaveportal { crypto default token lifetime {$AUTH_TOKEN_LIFETIME} enable identity store localdb cookie domain {$REMNAWAVE_PANEL_DOMAIN} ui { links { "Remnawave" "/dashboard/home" icon "las la-tachometer-alt" "My Identity" "/r/whoami" icon "las la-user" "API Keys" "/r/settings/apikeys" icon "las la-key" "MFA" "/r/settings/mfa" icon "lab la-keycdn" } } transform user { match origin local action add role authp/admin require mfa } } authorization policy panelpolicy { set auth url /r allow roles authp/admin with api key auth portal remnawaveportal realm local acl rule { comment "Accept" match role authp/admin allow stop log info } acl rule { comment "Deny" match any deny log warn } } } } https://{$REMNAWAVE_PANEL_DOMAIN} { route /api/* { reverse_proxy http://remnawave:3000 } handle /r { rewrite * /auth request_header +X-Forwarded-Prefix /r authenticate with remnawaveportal } route /r* { authenticate with remnawaveportal } route /* { authorize with panelpolicy reverse_proxy http://remnawave:3000 } } link.openode.xyz { reverse_proxy http://remnawave-subscription-page:3010 } Все данные у нас будут браться из environment, которые мы будем передавать в контейнер. ЕСЛИ ВЫ НЕ ХОТИТЕ ИСПОЛЬЗОВАТЬ ДВУХФАКТОРНУЮ АУТЕНТИФИКАЦИЮ ДЛЯ ВХОДА В ПАНЕЛЬ, ТО УДАЛИТЕ СТРОКУ ИЗ КОДА ВЫШЕ: require mfa 2.8. Создание файла контейнера для Caddy Создаем файл контейнера для Caddy: nano docker-compose.yml Вставляем содержимое: services: remnawave-caddy: image: remnawave/caddy-with-auth:latest container_name: 'remnawave-caddy' hostname: remnawave-caddy restart: always environment: - AUTH_TOKEN_LIFETIME=3600 - REMNAWAVE_PANEL_DOMAIN=remna.openode.xyz - AUTHP_ADMIN_USER=admin - AUTHP_ADMIN_EMAIL=admin@openode.xyz - AUTHP_ADMIN_SECRET=super-puper-openode ports: - '0.0.0.0:443:443' - '0.0.0.0:80:80' networks: - remnawave-network volumes: - ./Caddyfile:/etc/caddy/Caddyfile - remnawave-caddy-ssl-data:/data networks: remnawave-network: name: remnawave-network driver: bridge external: true volumes: remnawave-caddy-ssl-data: driver: local external: false name: remnawave-caddy-ssl-data Контейнер создали, но запускать пока не будем. Сеть мы заранее указали ту, которую создадим далее. 3. Установка панели 3.1. Создание файла docker-compose.yml Переходим в папку Remnawave и создаем файл docker-compose.yml: cd /opt/remnawave/ && nano docker-compose.yml Устанавливать будем latest-ветку, так как там сейчас все самые полезные функции. В скором времени будет релиз 1.5.0 в latest, поэтому можно будет смело его брать за базу. services: remnawave-db: image: postgres:17 container_name: 'remnawave-db' hostname: remnawave-db restart: always env_file: - .env environment: - POSTGRES_USER=${POSTGRES_USER} - POSTGRES_PASSWORD=${POSTGRES_PASSWORD} - POSTGRES_DB=${POSTGRES_DB} - TZ=UTC ports: - '127.0.0.1:6767:5432' volumes: - remnawave-db-data:/var/lib/postgresql/data networks: - remnawave-network healthcheck: test: ['CMD-SHELL', 'pg_isready -U $${POSTGRES_USER} -d $${POSTGRES_DB}'] interval: 3s timeout: 10s retries: 3 remnawave: image: remnawave/backend:latest container_name: 'remnawave' hostname: remnawave restart: always ports: - '127.0.0.1:3000:3000' env_file: - .env networks: - remnawave-network depends_on: remnawave-db: condition: service_healthy remnawave-redis: image: valkey/valkey:8.0.2-alpine container_name: remnawave-redis hostname: remnawave-redis restart: always networks: - remnawave-network volumes: - remnawave-redis-data:/data remnawave-subscription-page: image: remnawave/subscription-page:latest container_name: remnawave-subscription-page hostname: remnawave-subscription-page restart: always environment: - REMNAWAVE_PANEL_URL=http://remnawave:3000 # Здесь мы указали контейнер и порт контейнера. Но если у вас страница будет стоять отдельно, вы должны указать здесь домен для панели - APP_PORT=3010 - META_TITLE="Subscription Page Title" - META_DESCRIPTION="Subscription Page Description" ports: - '127.0.0.1:3010:3010' networks: - remnawave-network networks: remnawave-network: name: remnawave-network driver: bridge external: false volumes: remnawave-db-data: driver: local external: false name: remnawave-db-data remnawave-redis-data: driver: local external: false name: remnawave-redis-data Для страницы подписки замените в - REMNAWAVE_PLAIN_DOMAIN=remna.openode.xyz на ВАШ домен панели Можно также добавить для страницы подписки параметр ниже: - CUSTOM_SUB_PREFIX=sub тогда получится такой вариант: remnawave-subscription-page: image: remnawave/subscription-page:latest container_name: remnawave-subscription-page hostname: remnawave-subscription-page restart: always environment: - REMNAWAVE_PANEL_URL=http://remnawave:3000 - SUBSCRIPTION_PAGE_PORT=3010 - META_TITLE="Subscription Page Title" - META_DESCRIPTION="Subscription Page Description" - CUSTOM_SUB_PREFIX=sub ports: - '127.0.0.1:3010:3010' networks: - remnawave-network После этих изменений, у вас к адресу подписки добавится дополнительный параметр в url: link.openode.xyz/sub/<uuid> Тогда и для .env (который мы будем формировать дальше) нужно будет указывать правильный параметр для sub_public_domain SUB_PUBLIC_DOMAIN=link.openode.xyz/sub Сохранили и закрыли. 3.2. Создание файла .env Создаем здесь же файл .env: nano .env И вставляем в него содержимое из файла по ссылке: https://github.com/remnawave/backend/blob/main/.env.sample Я приведу сразу готовый свой файл: cd ~/remnawave/ && nano docker-compose.yml ### APP ### APP_PORT=3000 METRICS_PORT=3001 ### API ### # Possible values: max (start instances on all cores), number (start instances on number of cores), -1 (start instances on all cores - 1) # !!! Do not set this value more that physical cores count in your machine !!! API_INSTANCES=max ### DATABASE ### # FORMAT: postgresql://{user}:{password}@{host}:{port}/{database} DATABASE_URL="postgresql://postgres:postgres@remnawave-db:5432/postgres" ### REDIS ### REDIS_HOST=remnawave-redis REDIS_PORT=6379 ### JWT ### ### CHANGE DEFAULT VALUES ### JWT_AUTH_SECRET=6ac5b3ba99b94d9e0f6b9c242691c14e3bd54492b60aff7829e6b050535d8827278c098b42d6833a314af104f2c9da8046c33a14f45c00c43117dda0ba4ea25866a3562babea7ac59c523fea04cab6c24c4f191846b73ac7420fb265b0f910ad09018f662e8daf7e6bf8173546d89687fdb839fd14f34e754b20ae1e1d556ee3 JWT_API_TOKENS_SECRET=b3e86a783d3ca63941fe48eb2fdf8901fa294b777376c77b852c98cab8e136d12f4a0b0c898a60cdda6c1a76af6f7a9acdd292a4040bc0a4a7c34091ddb25158aa785c90391e094672da646712d2ae1e6f7e2bada14a2deb9099c291bc464115fb0ae71d042baacc8f7890ea55d8eb6a42d474604429978880e851632ce187a6 ### TELEGRAM ### IS_TELEGRAM_NOTIFICATIONS_ENABLED=false #TELEGRAM_NOTIFY_USERS_CHAT_ID=change_me #TELEGRAM_NOTIFY_NODES_CHAT_ID=change_me #TELEGRAM_NOTIFY_USERS_THREAD_ID=change_me #TELEGRAM_NOTIFY_NODES_THREAD_ID=change_me TELEGRAM_OAUTH_ENABLED=false ### or TRUE (required IS_TELEGRAM_NOTIFICATIONS_ENABLED=true) TELEGRAM_OAUTH_ADMIN_IDS=change_me ### FRONT_END ### FRONT_END_DOMAIN=remna.openode.xyz ### SUBSCRIPTION PUBLIC DOMAIN ### ### RAW DOMAIN, WITHOUT HTTP/HTTPS, DO NOT PLACE / to end of domain ### ### Used in "profile-web-page-url" response header ### SUB_PUBLIC_DOMAIN=link.openode.xyz ### SWAGGER ### SWAGGER_PATH=/docs SCALAR_PATH=/scalar IS_DOCS_ENABLED=false ### PROMETHEUS ### ### Metrics are available at /api/metrics METRICS_USER=admin METRICS_PASS=admin ### WEBHOOK ### WEBHOOK_ENABLED=false ### Only https:// is allowed WEBHOOK_URL=https://webhook.site/1234567890 ### This secret is used to sign the webhook payload, must be exact 64 characters. Only a-z, 0-9, A-Z are allowed. WEBHOOK_SECRET_HEADER=vsmu67Kmg6R8FjIOF1WUY8LWBHie4scdEqrfsKmyf4IAf8dY3nFS0wwYHkhh6ZvQ ### CLOUDFLARE ### # USED ONLY FOR docker-compose-prod-with-cf.yml # NOT USED BY THE APP ITSELF # CLOUDFLARE_TOKEN=ey... ### Database ### ### For Postgres Docker container ### # NOT USED BY THE APP ITSELF POSTGRES_USER=postgres POSTGRES_PASSWORD=postgres POSTGRES_DB=postgres Для того что бы включить oAuth Telegram авторизацию - вы должны внести в вашего бота через @botfather параметр домена панели. Обязательно заменяйте все JWT-секреты на свои. Значения генерируем здесь: https://jwtsecret.com/generate 4. Запуск панели 4.1. Запуск контейнера Remnawave Поднимаем наш контейнер Remnawave: cd /opt/remnawave && docker compose up -d 4.2. Запуск контейнера Caddy Поднимаем наш контейнер Caddy: cd caddy && docker compose up -d 5. Настройка панели 5.1. Авторизация Зайдя на домен: remna.openode.xyz Видим следующее: Проходим авторизацию, в моем случае это было: admin@openode.xyz super-puper-openode 5.2. Создание токена MFA Теперь идет запрос, что нам нужно создать токен для многофакторной аутентификации. Если вы все сделали корректно, увидите окно регистрации в Remnawave: Я задал свои параметры и сохранил пароль в надежном месте. Панель готова! Создадим первого пользователя и проверим, что страница подписки работает корректно. 6. Обновление конфигурации 6.1. Обновление конфига Заходим на дашборде на страницу «Конфиг» и заменяем все содержимое на: { "log": { "loglevel": "warning" }, "inbounds": [ { "tag": "Vless TCP reality", "port": 443, "listen": "0.0.0.0", "protocol": "vless", "settings": { "clients": [], "decryption": "none" }, "sniffing": { "enabled": true, "destOverride": [ "http", "tls" ] }, "streamSettings": { "network": "tcp", "security": "reality", "tcpSettings": {}, "realitySettings": { "dest": "ftp.debian.org:443", "show": false, "xver": 0, "shortIds": [ "" ], "publicKey": "22mH2kO_6Q43slZjf-njD9TMv9xeYMA1P28PzEtqOWo", "privateKey": "Jy4FdQWKBOtLc2rvJqRxP-WMELzNhRxmUgequcAcLhQ", "serverNames": [ "ftp.debian.org" ] } } }, { "tag": "SS", "port": 8580, "listen": "0.0.0.0", "protocol": "shadowsocks", "settings": { "clients": [], "network": "tcp,udp" } } ], "outbounds": [ { "tag": "DIRECT", "protocol": "freedom", "settings": { "domainStrategy": "ForceIPv4" } }, { "tag": "BLOCK", "protocol": "blackhole" }, { "tag": "IPv4", "protocol": "freedom", "settings": { "domainStrategy": "ForceIPv4" } } ], "routing": { "rules": [ { "type": "field", "domain": [ "full:cloudflare.com", "domain:msftconnecttest.com", "domain:msftncsi.com", "domain:connectivitycheck.gstatic.com", "domain:captive.apple.com", "full:detectportal.firefox.com", "domain:networkcheck.kde.org", "full:*.gstatic.com", "domain:gstatic.com" ], "outboundTag": "DIRECT" }, { "type": "field", "protocol": [ "bittorrent" ], "outboundTag": "BLOCK" }, { "ip": [ "geoip:private" ], "type": "field", "outboundTag": "BLOCK" } ], "domainStrategy": "IPIfNonMatch" } } 6.2. Генерация ключей После этого обязательно генерируем пару ключей: Копируем эту пару ключей и заменяем содержимое в конфигурации VLESS (чтобы ваши ключи были уникальными). 7. Работа с инбаундами 7.1. Просмотр инбаундов Идем на вкладку «Инбаунды» и видим: Все инбаунды у нас автоматически подтянулись. Можно посмотреть самые важные характеристики, а также есть кнопка для массового управления ими. 8. Подключение ноды НОДА - это отдельный сервер xray, который будет на себя принимать подключения. Нода может быть установлена на одном сервере с панелью. Но это не рекомендуется по разным объективным причинам - безопасность, стабильность, скорость. Исключения составляет "соло" использование панели, например чисто для себя одного, и в таком варианте, использовать два сервера, один из которых чисто под панель, а второй под ноду - затратно. Нода это обычно зарубежный сервер. Ноды мы добавляем чтобы потом к ним подключаться. Системный требования для ноды ниже чем для панели. Обычно хватает 1 ядро, 2гб памяти и 10гб места. Если у вас нодой будут пользоваться достаточно большое количество человек, то имейте ввиду, что будут расти требования к процессору. Вот простая схема требований к ноде. до 70-100 человек (в зависимости от сетевой нагрузки) - 1 ядро 1гб до 300 человек - 2 ядра - 2 гб 10гб\с порт. до 600-800 человек - 4 ядра 8гб, и минимум 10гб\с порт. больше 1000 человек - лучше балансировку ноды, хотя бы по DNS. 8.1. Создание новой ноды Переходим в «Ноды» 2 и жмем «Создать новую ноду».. Появится такое окно Его не закрываем. Сейчас оно нам нужно для копирования ключа, а дальше мы заполним параметры сервера для подключения. 8.2. Подключение к серверу ноды Подключаемся к серверу нашей ноды (я использую Termius). 8.3. Установка скрипта ноды sudo bash -c "$(curl -sL https://github.com/DigneZzZ/remnawave-scripts/raw/main/remnanode.sh)" @ install 8.4. Ввод данных сертификата Будет предложено ввести данные сертификата из панели: Копируем из нашей панели: И вставляем как есть в нашу консоль. Дважды жмем Enter после вставки (чтобы появилась пустая строка, тогда он перейдет на следующий этап). Указываем порт (по умолчанию он 3000, можно нажать Enter). Далее задаст вопрос, хотите ли вы установить последнее ядро Xray-core (если нажать Enter, он это пропустит), но установить можно будет потом отдельно. И все. Готово. Контейнер запустится и будет ждать подключений: 8.5. Настройка параметров сервера Возвращаемся в нашу панель. Задаем параметры нашего сервера: ЗАПОМНИТЕ РАЗ И НА ВСЕГДА! ПОДКЛЮЧАЕМ НОДУ ТОЛЬКО IP-АДРЕСУ! НЕ ПО ДОМЕНУ! ДОМЕН МОЖНО УКАЗАТЬ ТОЛЬКО В НАСТРОЙКАХ ХОСТА!!! Жмем «Сохранить». Увидим сначала попытку подключения: Затем статус, что подключен: 9. Создание хостов 9.1. Создание хоста Последняя, заключительная часть создания подключения — это создание хостов. В Marzban они создавались автоматически. Здесь они создаются вручную. Идем во вкладку «Хосты». Жмем «Создать хост». Заполняем данные: Примечание — это то, как вы назовете сами свой хост и как он будет отображаться у пользователя. Например, Sweden. И к имени можно будет добавить переменные: Мы добавим только Days_left. В адресе ноды указываем либо IP-адрес сервера, либо поддомен, привязанный к этому серверу. Я укажу поддомен (это удобнее: в случае смены сервера достаточно будет поменять DNS-запись для этого адреса на новый сервер-ноду, и для пользователя смена пройдет незаметно). Выбираем наш инбаунд. А порт у нас подтянется самостоятельно из конфигурации. И ОБЯЗАТЕЛЬНО ДЕРНИТЕ СЕРЫЙ ФЛАЖОК , ПЕРЕВЕДЯ ЕГО В СОСТОЯНИЕ ВКЛЮЧЕННОГО Не знаю, как сейчас, но на некоторых клиентах была проблема, что Fingerprint не проставлялся автоматически. Поэтому давайте зададим его по умолчанию: Выбираем Chrome. Жмем «Сохранить». Готово! 9.2. Привязка инбаундов для пользователей Для уже созданных пользователей инбаунды нужно прописать принудительно, для всех новых создаваемых пользователей вы и так будете выбирать. Поэтому вернемся на вкладку «Инбаунды». И научимся работать с массовыми действиями. Включим Vless-инбаунд для ВСЕХ (но у нас это для нашего единственного пользователя): И получим такой результат: Готово! Чтобы сбросить пароль администратора (для входа в панель) или сертификаты, есть специальная консольная CLI-команда (выполнять на сервере с мейном): docker exec -it remnawave remnawave И получим такие варианты:
 5 баллов
5 баллов -
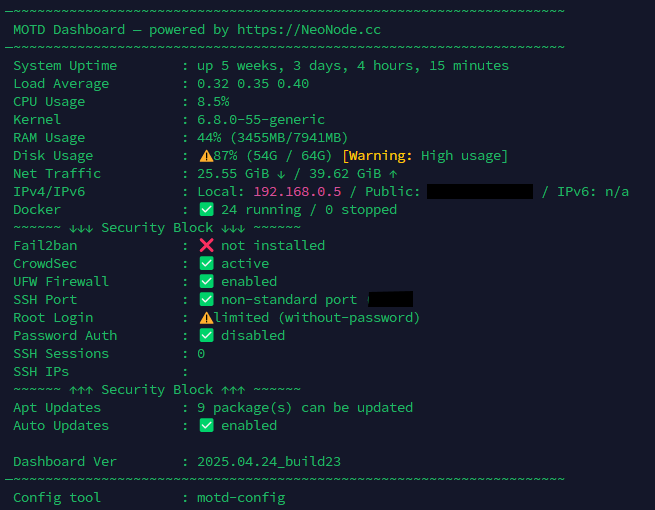
Новый MOTD-дэшборд от NeoNode Теперь это не просто приветствие при входе, а полноценный системный дашборд — всё самое важное о сервере прямо в терминале. Установка Обычный режим (для root bash <(wget -qO- https://dignezzz.github.io/server/dashboard.sh) --force Режим для обычного пользователя (без root) (не рекомендуется): bash <(wget -qO- https://dignezzz.github.io/server/dashboard.sh) --force --not-root Настройка отображаемых блоков: motd-config Что умеет дашборд Аптайм, загрузка CPU, RAM, диск, ядро IP-адреса: локальный, публичный и IPv6 Поддержка Docker — видны остановленные и «упавшие» контейнеры Проверка безопасности: SSH-порт, root-доступ, вход по паролю Статус UFW, Fail2Ban, CrowdSec Сетевой трафик (vnstat) Состояние обновлений APT и автообновлений Проверка актуальности версии дашборда (обновление по ссылке) 🛠 Гибкая настройка Каждый блок можно включить или отключить Конфиг сохраняется в /etc/motdrc или ~/.motdrc Управление через интерактивную утилиту motd-config Поддержка обычных пользователей (работает даже в LXC, Proxmox, WebSSH) (но очень урезанная и должен быть установлен нужный софт) Пример: хочешь скрыть Docker, автообновления и IP — отключи через motd-config, и они исчезнут из дашборда. Преимущества Работает «из коробки» — без лишних зависимостей Не требует crontab или внешних API Отображает только нужную тебе информацию Статусы с эмодзи ( ) — читается моментально Поддержка монохромных терминалов — не сломается в Proxmox или LXC Обновление от 24.04.2025: Удалены tput-цвета — теперь нет багов в «серых» терминалах Подсвечены критичные риски: root-доступ, UFW, fail2ban Выводит ядро и SSH-настройки Автообновление версии через GitHub Pages Есть предложения, баги или хочешь добавить свой блок — читай в Telegram канале или комментируй в теме!
3 балла
-
Вы пытаетесь максимально замаскировать свой VPN или proxy? Тогда вам наверняка необходимо убрать определение туннеля (двусторонний пинг). Перейдём к ознакомлению: В гайде повествуется об отключении определения туннеля на OC Linux и Windows. Запускаем ssh, переходим на сервер и логинимся под root пользователем Переходим к редактированию настроек ufw c помощью nano: nano /etc/ufw/before.rules Добавляем новую строку и сохраняем результат: # ok icmp codes -A ufw-before-input -p icmp --icmp-type destination-unreachable -j DROP -A ufw-before-input -p icmp --icmp-type source-quench -j DROP -A ufw-before-input -p icmp --icmp-type time-exceeded -j DROP -A ufw-before-input -p icmp --icmp-type parameter-problem -j DROP -A ufw-before-input -p icmp --icmp-type echo-request -j DROP 4. Перезапускаем фаервол ufw ufw disable && ufw enable 5. Сервер больше не должен отправлять ICMP трафик, а значит вам удалось скрыть двусторонний пинг!2 балла
-
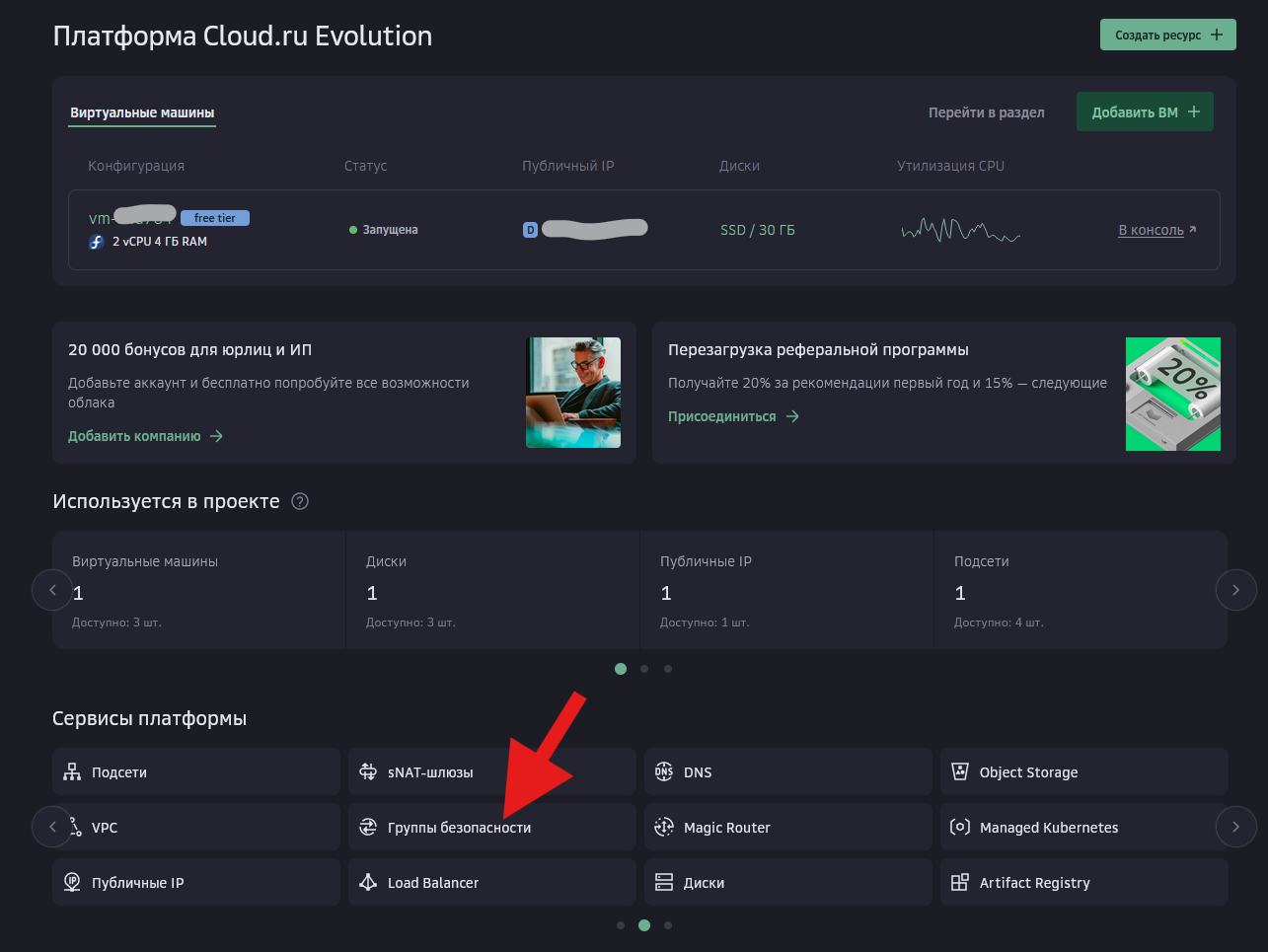
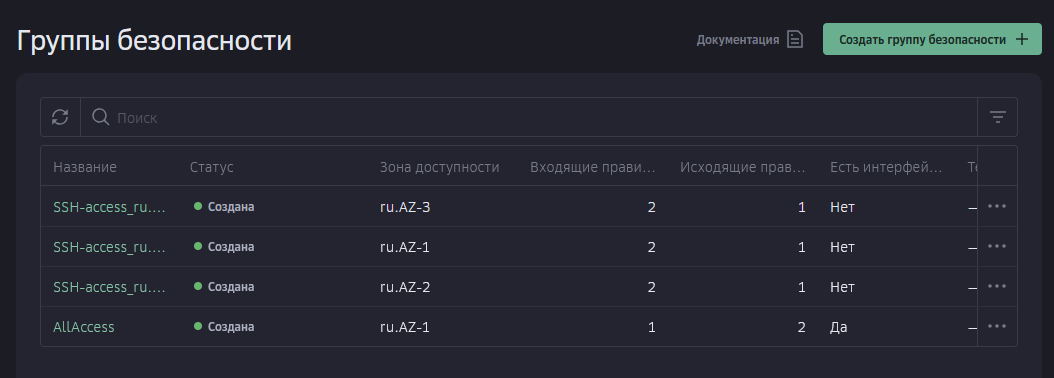
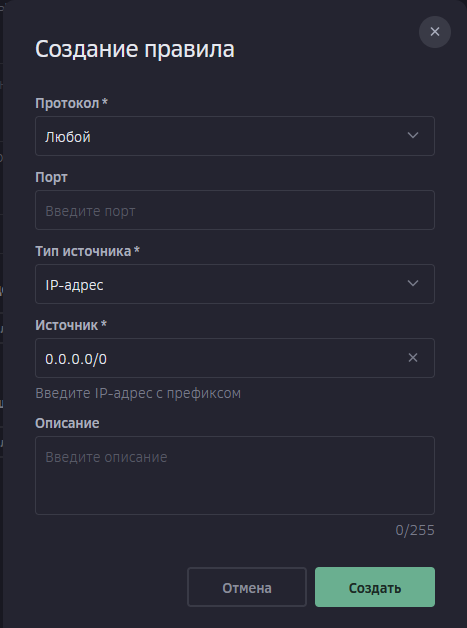
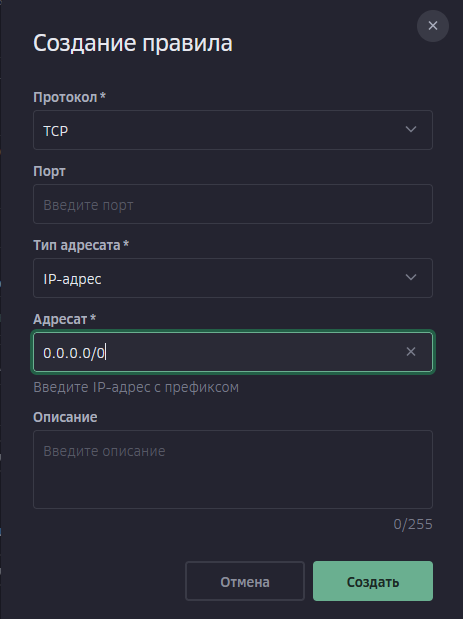
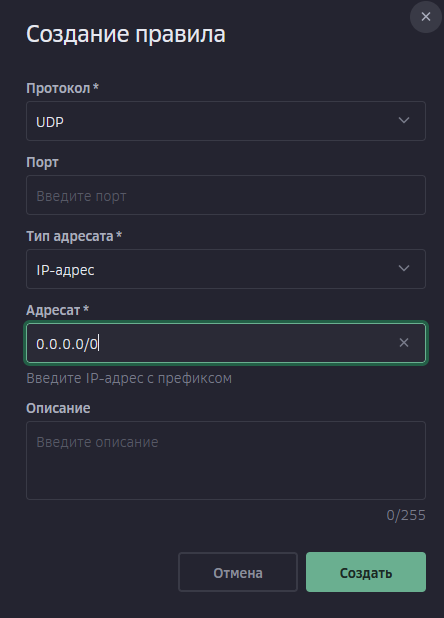
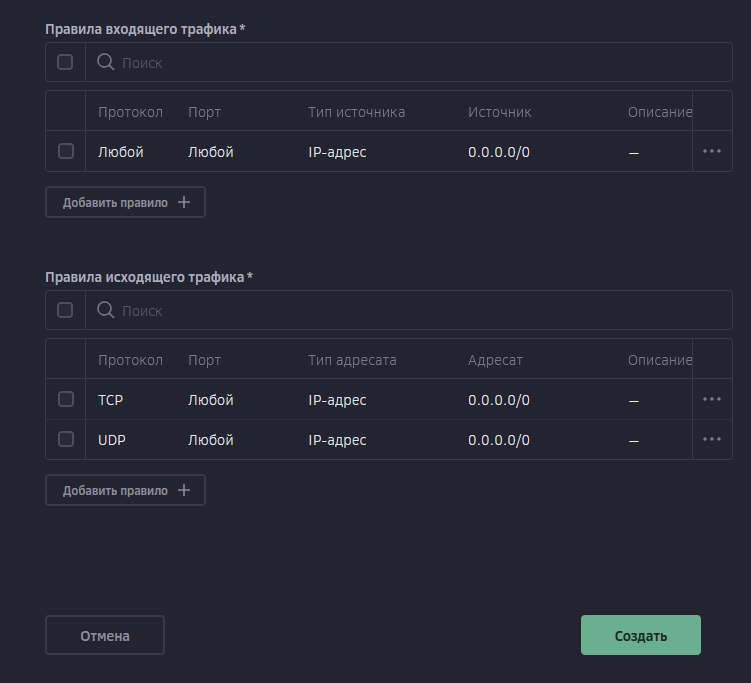
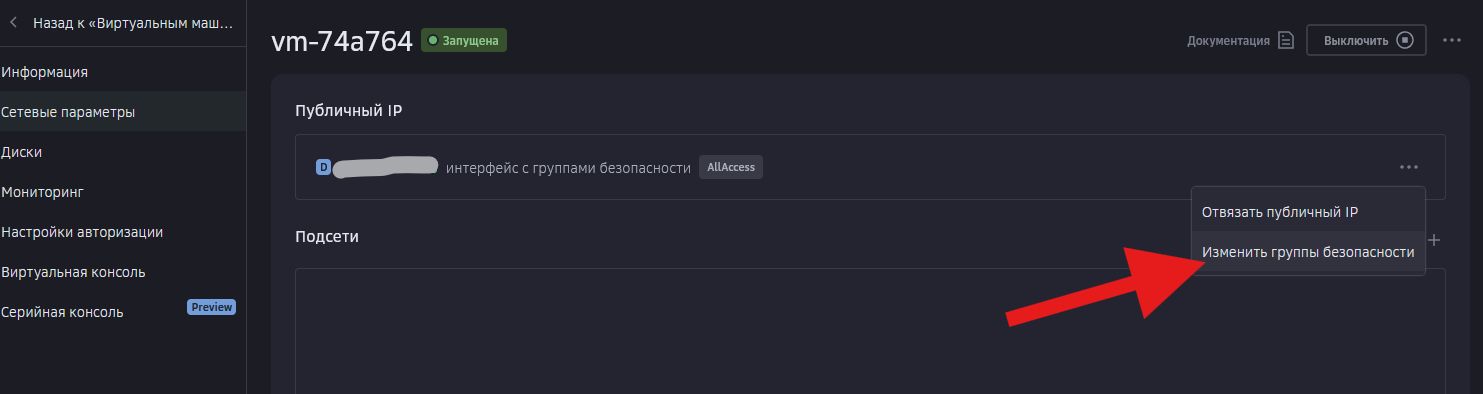
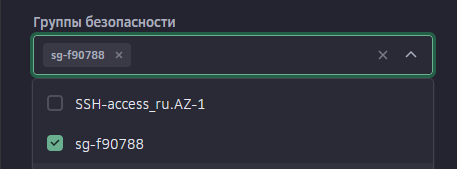
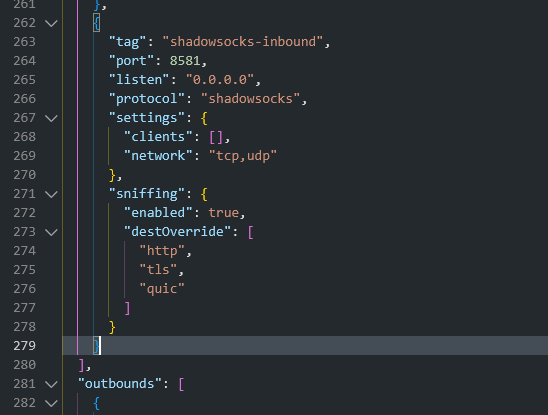
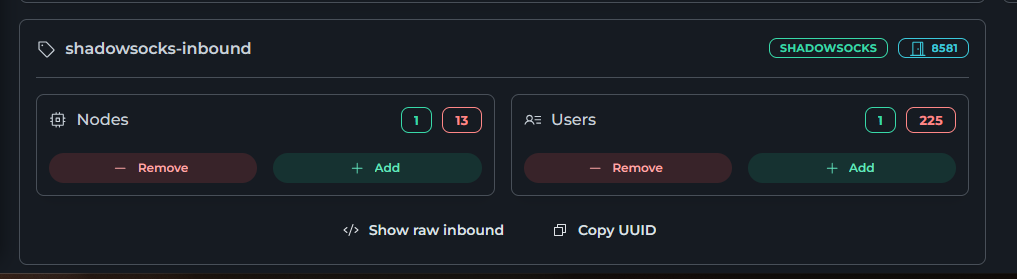
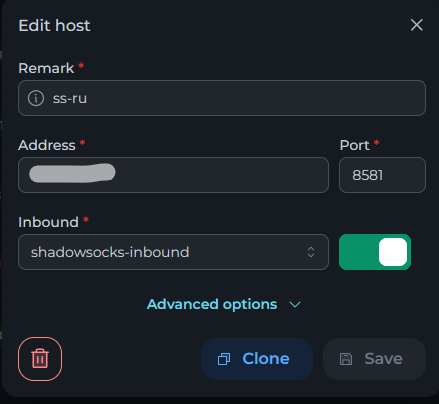
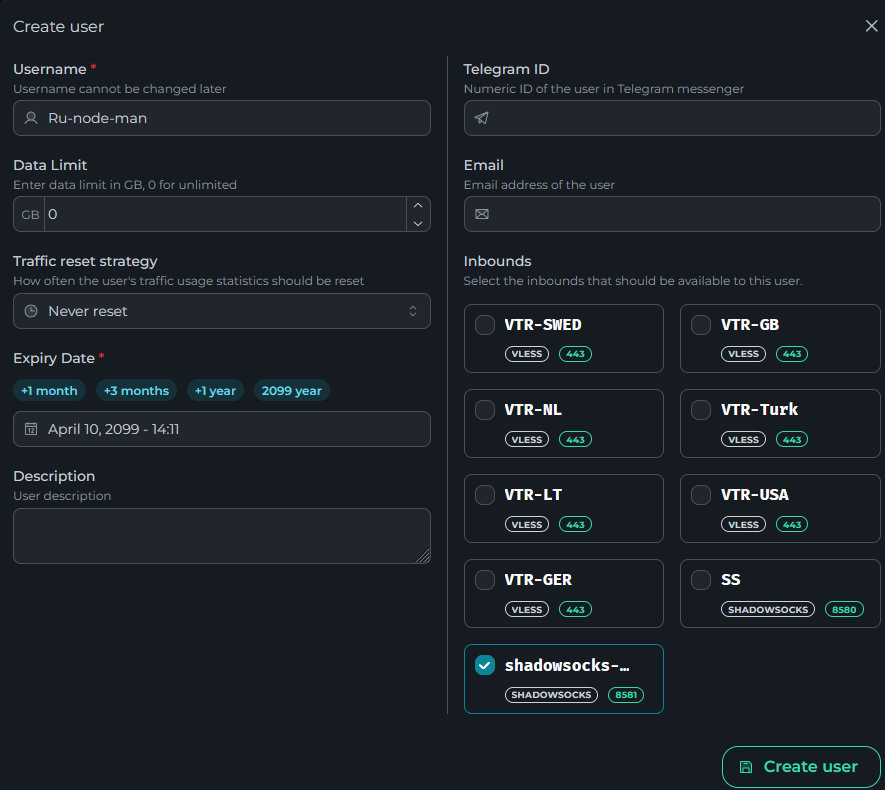
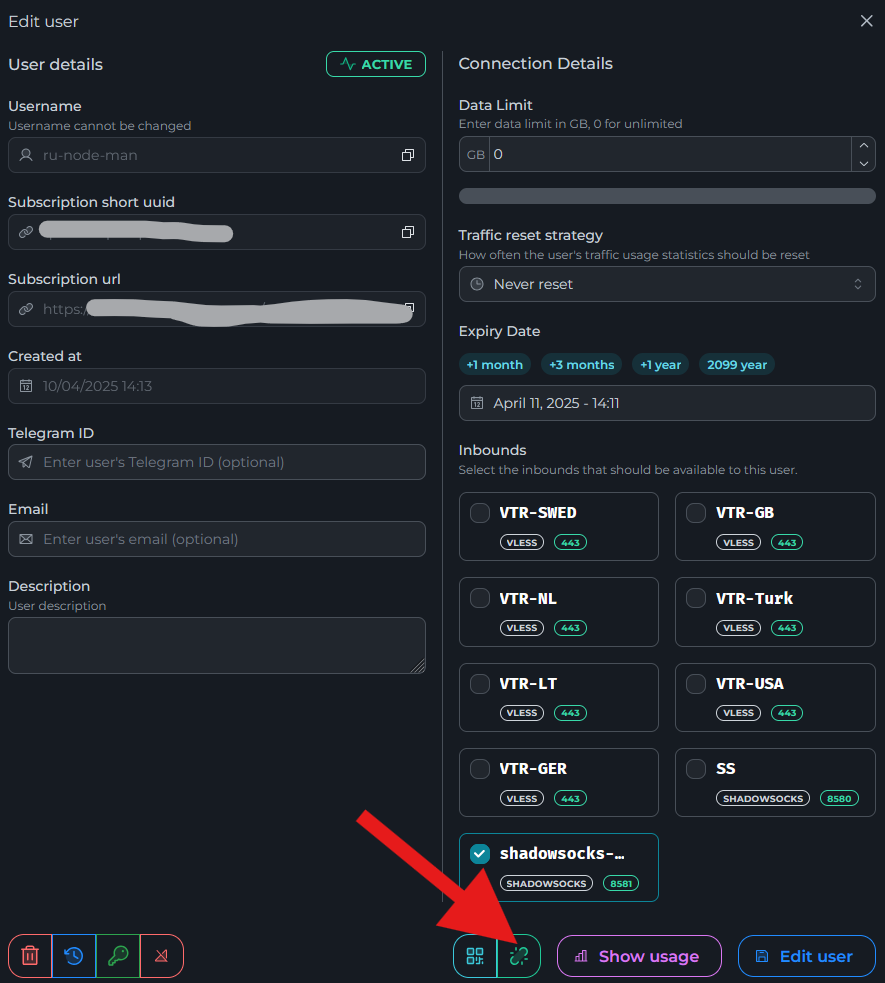
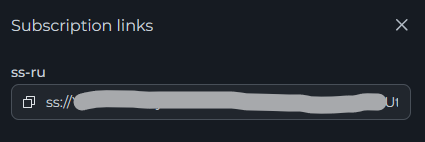
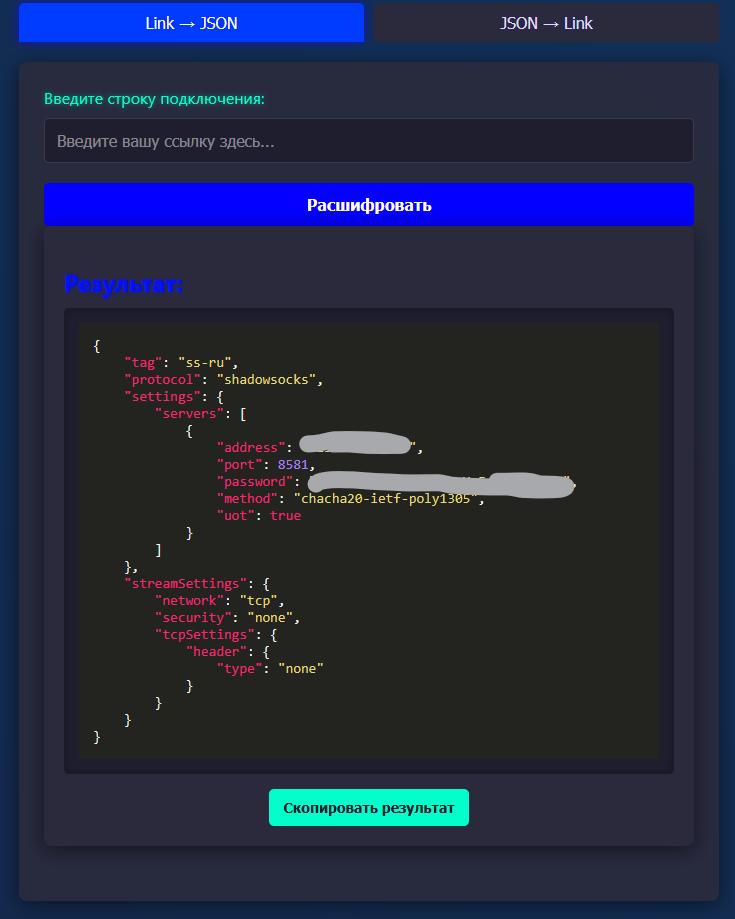
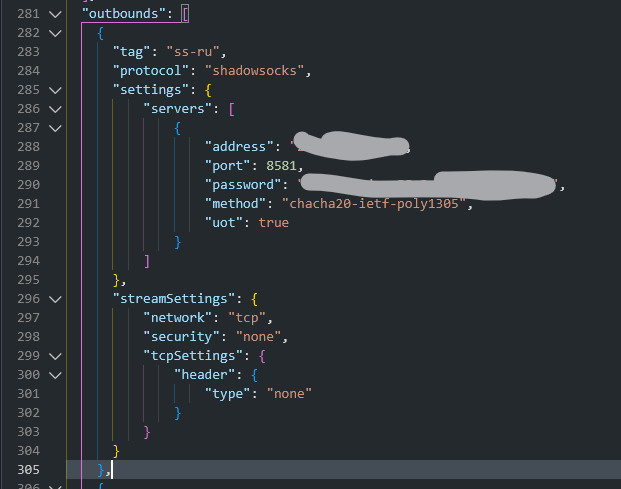
Всем привет! Когда был Marzban, я рассказывал как отправить YouTube трафик через РФ сервер, но с использованием отдельной панели 3x-ui. Вот эта тема: https://openode.xyz/topic/1213-otpravlyaem-youtube-cherez-rossiyskiy-server-s-pomoschyu-3x-ui/ Сейчас мы сделаем немного по другому, и удобнее, как мне кажется. 1. Выбор РФ сервера. Тема достаточно спорная, и в действительности найти достойный РФ сервер достаточно проблемно. Возможные варианты: cloud.vk.com (от 1000 рублей) cloud.ru (можно зайти на Free Tier, получить 4000 бонусных рублей на 2 месяца, а потом продолжить пользоваться бесплатным сервером оплачивая только ipv4 за 170р в месяц) selectel.ru - От 900 рублей, но там есть лимит трафика - 3тб в месяц НА АККАУНТ. Предлагаю остановиться на cloud.ru. 2. Настройка Фаервола сервера на Cloud.ru После оформления сервера у вас будет доступен только 22 порт. Фаервол на клауд.ру достаточно сложный, поэтому бегло покажу как разрешить всё. А рулить потом можете самостоятельно через UFW, например. 2.1. На главной странице находим Группы безопасности 2.2. Выбираем создание новой (зеленая кнопка справа) 2.3. Заполняем на скриншотах ниже Правило входящего трафика: Правило исходящего трафика: Разбиваем на TCP и UDP В итоге получилось чтобы так: И жмем - Создать. 2.3. Теперь идем в нашу Виртуальную машину. Заходим в "Сетевые параметры" Жмем Изменить группы безопасности И оставляем ТОЛЬКО ту которую мы создали ранее Галочку с SSH-access_ru убираем!!! Готово! 3. Создаем ноду для Remnawave. Читаем внимательно пункт 8 из прошлого поста: 4. Создаем новый Inbound на базе ShadowSocks, который мы будем использовать для подключения к ноде. { "tag": "shadowsocks-inbound", "port": 8581, "listen": "0.0.0.0", "protocol": "shadowsocks", "settings": { "clients": [], "network": "tcp,udp" }, "sniffing": { "enabled": true, "destOverride": [ "http", "tls", "quic" ] } } Я его вставил в конец, перед Outbound-ом. 5. Перейдем в Inbounds и проверим что у нас он создался: 6. Идем в HOSTS и создаем новый: Указав в Address - айпи нашего РФ сервера: 7. Создаем нового пользователя, и включаем ему единственный инбаунд: (не забудьте указать безлимит по трафику и по сроку действия!) 8. заходим в пользователя и жмем на кнопку где стрелка: Копируем ссылку: 9. Теперь нужно конвертировать в тег подключения. Идем на мой конвертер: https://decode.neonode.cc Вставляем ссылку, и жмем расшифровать. Копируем полученный результат. 10. Возвращаемся в конфигурацию XRAY в панеле 11. Добавляем новый OUTBOUND, в соответствии с тем что скопировали на шаге 9. Запоминаем имя тэга: ss-ru но вы можете переименовать как хотите! Главное не путайтесь! 12. Создаем новое правило в routing Я приведу сразу весь блок с роутингом "routing": { "rules": [ { "type": "field", "domain": [ "full:cloudflare.com", "domain:msftconnecttest.com", "domain:msftncsi.com", "domain:connectivitycheck.gstatic.com", "domain:captive.apple.com", "full:detectportal.firefox.com", "domain:networkcheck.kde.org", "full:*.gstatic.com", "domain:gstatic.com" ], "outboundTag": "DIRECT" }, { "type": "field", "domain": [ "geosite:youtube", "ggpht.cn", "ggpht.com", "full:googlevideo.com", "gvt1.com", "youtube.ru", "youtube-nocookie.com", "gvt2.com", "video.google.com", "wide-youtube.l.google.com", "withyoutube.com", "youtu.be", "youtube.com", "youtubeeducation.com", "youtubeembeddedplayer.googleapis.com", "youtubefanfest.com", "youtubegaming.com", "youtubego.co.id", "youtubego.co.in", "youtubego.com", "youtubego.com.br", "youtubego.id", "youtubego.in", "youtubei.googleapis.com", "youtubekids.com", "youtubemobilesupport.com", "yt.be", "ytimg.com", "2ip.io" ], "inboundTag": [ "VTR-GER", "VTR-USA", "VTR-LT", "VTR-Turk", "VTR-NL", "VTR-GB", "VTR-SWED" ], "outboundTag": "ss-ru" }, { "type": "field", "protocol": [ "bittorrent" ], "outboundTag": "BLOCK" }, { "ip": [ "geoip:private" ], "type": "field", "outboundTag": "BLOCK" } ], "domainStrategy": "IPIfNonMatch" } Обратите внимание на блок InboundTag! У меня этот блок inboundTag содержит в себе ВСЕ ТЕГИ моих ИНБАУНДОВ КРОМЕ ТЕГА shadowsocks-inbound!!!! ЭТО ОЧЕНЬ ВАЖНО! ЕСЛИ ВЫ УКАЖЕТЕ ТЕГ shadowsocks-inbound - ТО У ВАС ТРАФИК БУДЕТ ГОНЯТЬСЯ ПО КРУГУ И НИЧЕГО НЕ ОТКРОЕТСЯ!!!! "inboundTag": [ "VTR-GER", "VTR-USA", "VTR-LT", "VTR-Turk", "VTR-NL", "VTR-GB", "VTR-SWED" ТЕГА shadowsocks-inbound В ЭТОМ СПИСКЕ НЕ ДОЛЖНО БЫТЬ!!!! Вот в принципе и всё. Пользуйтесь! PS: 2ip.io я добавил в перечень доменов - исключительно для проверки, что все правила у нас работают! Благодаря этому, мы легко сможем: Мониторить состояние ноды Мониторить потребление трафика Подключить ещё Ру-сервера для балансировки нагрузки, если у вас она высокая
2 балла
-
Сделал вот так, указал inboundTag "rules": [ { "domain": [ "geosite:category-ru" ], "inboundTag": "Vless TCP reality", "outboundTag": "RU" }, Теперь все пошло через ру ноду...1 балл
-
Подскажите пожалуйста, а можно ли сделать гео роутинг как в схеме с двойным vpn, чтобы ru сайты открывались через ru сервер, а зарубежные через зарубежный сервер соответственно? UPD Разобрался1 балл
-
Hi, Thanks for your question. Currently, the forum focuses mainly on detailed installation and configuration guides for panels like Remnawave and Marzban. There is no dedicated content or templates tailored for bypassing censorship in Iran at this time. Most examples are generic or geared toward Russia. That said, some users have reported limited success with configurations using VLESS + Reality, XTLS, or fallback with CDN domains, but this depends heavily on the current network situation in Iran, which changes often.1 балл
-
По сей день. Проверь порядок правил в файле. В iptables - чем выше в списке правило, тем больше его приоритет. В ufw - наоборот1 балл
-
С 31.03.2025 компоновка приложений в subscription-page в remnawave стала максимально адаптивной и удобной. Инструкции я напишу чуть позже. А пока покидаю просто свои подборки с приложениями и конфигурациями. Информация об этом есть на странице: https://remna.st/subscription-templating/client-configuration Максимально полный вариант. app1.json
1 балл
-
Панель обновлять можно как у тебя на примере. Если установить дополнительно вышедший сегодня скрипт: https://github.com/DigneZzZ/remnawave-scripts/blob/main/README_RU.md#-установщик-remnawave-panel То команды будут проще: remnawave update Ноду можно и так как ты показал, но можно и через скрипт, если ты его ставил: remnanode update Ядра только на нодах. Поэтому можно командой remnanode core-update1 балл
-
о, так все просто оказывается, спасибо. я думал там на другой сервер бэкенд подписки надо класть))1 балл
-
подскажите как получить одобренный пост? Хотел просмотреть инструкцию по double vpn1 балл
-
понял,спасибо)1 балл
-
Резервное копирование Keenetic + Entware Если на роутер установлена дополнительная система Entware, можно использовать скрипт, создающий резервную копию настроек роутера, прошивки и Entware с настройками. После выполнения — приходит Telegram-уведомление. Скрипт создан на основе обсуждения на форуме Keenetic Community: форум. Скрипт #!/opt/bin/bash set -x export PATH=/opt/bin:/opt/sbin:/bin:/usr/bin:/usr/sbin:/sbin # =========== НАСТРОЙКИ ============ CONFIG_FILE="/opt/etc/backup_config.env" if [[ ! -f $CONFIG_FILE ]]; then echo " Конфигурационный файл $CONFIG_FILE отсутствует!" exit 1 fi # Импорт конфигурации source "$CONFIG_FILE" DATE=$(date +%Y-%m-%d_%H-%M-%S) ARCHIVE_NAME="keenetic_backup_${DATE}.tar.gz" ARCHIVE_PATH="${LOCAL_TMP_DIR}/${ARCHIVE_NAME}" # Логирование в syslog log() { logger "[BACKUP]: $1" echo "$(date +%Y-%m-%d_%H:%M:%S) $1" | tee -a "$LOG_FILE" } # Отправка Telegram уведомлений send_telegram() { MESSAGE=$(echo -e "$1" | sed 's/$/%0A/g') curl -s -X POST "https://api.telegram.org/bot$TELEGRAM_TOKEN/sendMessage" \ -d chat_id="$TELEGRAM_CHAT_ID" \ -d message_thread_id="$TELEGRAM_THREAD_ID" \ -d parse_mode="Markdown" \ -d text="$MESSAGE" } # Очистка локальной директории cleanup_local() { log " Очистка локальной директории $LOCAL_BACKUP_DIR..." rm -rf "$LOCAL_BACKUP_DIR"/* || log " Не удалось очистить $LOCAL_BACKUP_DIR." log " Очистка локальной директории $LOCAL_TMP_DIR..." rm -rf "$LOCAL_TMP_DIR"/* || log " Не удалось очистить $LOCAL_TMP_DIR." } # Бэкап Entware backup_entware() { log " Создание бэкапа Entware..." tar cvzf ${LOCAL_BACKUP_DIR}/entware_backup_${DATE}.tar.gz -C /opt . > /dev/null } # Бэкап прошивки backup_firmware() { log " Создание бэкапа прошивки..." REL=$(ndmc -c 'show version' | grep 'release:' | awk '{print $2}') ndmc -c "copy flash:/firmware ${FW_BACKUP_DIR}/firmware-${REL}_${DATE}.bin" log " Создан бэкап прошивки: ${FW_BACKUP_DIR}/firmware-${REL}_${DATE}.bin" } # Бэкап конфига backup_config() { log " Создание бэкапа конфигурации..." ndmc -c "show running-config" > ${LOCAL_BACKUP_DIR}/config_${DATE}.cfg log " Создан бэкап конфигурации: ${LOCAL_BACKUP_DIR}/config_${DATE}.cfg" } # Архивация бэкапов create_archive() { log " Создание архива $ARCHIVE_NAME..." tar cvzf ${ARCHIVE_PATH} -C ${LOCAL_BACKUP_DIR} . > /dev/null || return 1 log " Архив создан: $ARCHIVE_PATH" } # Копирование на Nextcloud upload_to_nextcloud() { log " Копирование $ARCHIVE_PATH на Nextcloud..." curl -T ${ARCHIVE_PATH} -u ${NEXTCLOUD_USER}:${NEXTCLOUD_PASS} {$BACKUP_DIR_URL}/${ARCHIVE_NAME} log " Архив отправлен на Nextloud: $BACKUP_DIR_URL/${ARCHIVE_NAME}" } # Ротация бэкапов rotate_backups() { log " Получаем список бэкапов в Nextcloud..." # Получаем список бэкапов file_list=$(curl -s -u "$NEXTCLOUD_USER:$NEXTCLOUD_PASS" -X PROPFIND "$BACKUP_DIR_URL" -H "Depth: 1" \ | grep -oE "/remote.php/dav/files/[^<]*keenetic_backup_[^<]*\.tar\.gz") if [ -z "$file_list" ]; then log " Нет доступных бэкапов для ротации." return 0 fi echo "$file_list" | sort > /tmp/backups_sorted.txt total=$(wc -l < /tmp/backups_sorted.txt) # Удалим на один больше так как делаем новый бекап target_keep=$((KEEP_LAST - 1)) if [ "$total" -le "$target_keep"]; then log " Пока удалять нечего — всего $total бэкапов." return 0 fi delete_count=$((total - target_keep)) log " Удаляем $delete_count старых бэкапов..." head -n "$delete_count" /tmp/backups_sorted.txt | while read -r path; do filename=$(basename "$path") full_url="${BACKUP_DIR_URL}/${filename}" echo " Удаление: $full_url" curl -s -u ${NEXTCLOUD_USER}:${NEXTCLOUD_PASS} -X DELETE ${full_url} done log " Ротация завершена." } # =========== ОСНОВНОЙ СКРИПТ ============ main() { log "=== Начало резервного копирования ===" cleanup_local mkdir -p "$LOCAL_BACKUP_DIR" mkdir -p "$LOCAL_TMP_DIR" # Выполнение шагов backup_entware backup_firmware backup_config # Упаковка в единый архив create_archive # Ротация rotate_backups # Копирование на хранилища upload_to_nextcloud # Отправка отчета send_report log " Очистка локальной директории $LOCAL_TMP_DIR..." rm -rf "$LOCAL_TMP_DIR"/* || log " Не удалось очистить $LOCAL_TMP_DIR." send_telegram " Создана [резервная копия]($BACKUP_DIR_URL/$ARCHIVE_NAME) настроек роутера." log "=== Завершено ===" } main Установка скрипта # Путь к скрипту /opt/usr/bin/backup # Путь к конфигурации /opt/etc/backup_config.env # Сделать скрипт исполняемым chmod +x /opt/usr/bin/backup # Добавить в cron (ежедневно в 11:00) 0 11 * * * /opt/bin/bash /opt/usr/bin/backup Настройка backup_config.env KEEP_LAST=3 LOCAL_BACKUP_DIR="/tmp/mnt/Router/backups" FW_BACKUP_DIR="Router:/backups" LOCAL_TMP_DIR="/tmp/mnt/Router/tmp" LOG_FILE="/tmp/mnt/Router/backup.log" NEXTCLOUD_USER="user" NEXTCLOUD_PASS="password" BACKUP_DIR_URL="https://cloud.domain.ru/remote.php/dav/files/user/folder" TELEGRAM_TOKEN="token" TELEGRAM_CHAT_ID="CHAT_ID" # TELEGRAM_THREAD_ID="THREAD_ID" — удалить строку из скрипта, если не используете Что делает скрипт? Чистит временные директории Создаёт бэкап Entware (/opt) Создаёт бэкап прошивки Сохраняет текущую конфигурацию роутера Архивирует всё в keenetic_backup_*.tar.gz Отправляет архив на Nextcloud через WebDAV Удаляет старые резервные копии, оставляя только последние KEEP_LAST Отправляет Telegram-уведомление Альтернатива: rclone (не рекомендуется) Можно заменить curl на rclone для загрузки архива на облачные хранилища, например Google Drive. Однако, это сильно нагружает роутер. # Копирование на Google Drive upload_to_google_drive() { log " Копирование $ARCHIVE_PATH на Google Drive..." attempt_command "rclone copy $ARCHIVE_PATH $GDRIVE_REMOTE" "Копирование на Google Drive" } # Ротация бэкапов rotate_backups() { log " Ротация бэкапов старше $RETENTION_DAYS дней..." rclone delete --min-age "${RETENTION_DAYS}d" "$GDRIVE_REMOTE" && log " Ротация на GDrive завершена." rclone delete --min-age "${RETENTION_DAYS}d" "$MEGA_REMOTE" && log " Ротация на Mega завершена." } Восстановление Архив содержит три файла: config_* — конфигурация роутера firmware-* — прошивка роутера entware_backup_*.tar.gz — образ Entware со всеми настройками Для восстановления Entware — заменить стандартный архив установкой содержимого в install. Готово! Скрипт работает стабильно и регулярно делает резервные копии всех важных компонентов Keenetic + Entware. Если будут изменения, искать в оригинальной репе: https://deniom.ru/zametki/rezervnoe-kopirovanie-routera-keenetik/1 балл
-
Отвечу сам себе )) Проблема решилась изменением групп безопасности на cloud.ru1 балл
-
можешь просто сделать docker compose down && docker compose up -d1 балл
-
вон снизу написано" управление dns записями" создай там "panel.svoi-domen.com or .ru ...... пример "panel.luntik.ru" создаешь и вписываешь уже на сервере созданный домен1 балл
-
После замены значений, данные внутри контейнера уже не перетиhаются, так как Хранятся в Volume Пока контейнер запущен: docker exec remnawave-caddy rm /data/.local/caddy/users.json Затем docker compose down Редактируем docker-compose, ставим нужный пароль (без $!!!!!) Поднимаем docker compose up -d1 балл
-
Если кто то будет пересоздавать и у вас remnawave начнет писать forbidden, то есть не пускать вас. То перейдите к себе на сервер в /opt/remnawave/ введите там docker exec -it remnawave remnawave и стрелочками выберите ❯ Select an action ● Reset superadmin (Fully reset superadmin) ○ Reset certs ○ Exit reset superadmin - enter - yes1 балл
-
Так быстро сделал все по гайду. До страницы авторизации я дошел. Из отличий ставил не из dev, а latest.1 балл
-
Вот такой вариант. app2.json
1 балл
-
Двусторонний пинг на анонимность никак не влияет, просто доказывает то, что вы сидите через VPN1 балл













Эта таблица лидеров рассчитана в Москва/GMT+03:00